重要
- ① 学习过 JDK8 的特性,如:Lambda 表达式和 Stream API 等。
- ② 有一些项目开发经验,才能更好地理解并发编程。
- ③ 操作系统是 Windows 11 ,并安装了 VMWare WorkStation Pro 17.x 。
第一章:走进并发编程
1.1 为什么要使用并发编程?
使用并发编程的主要目的是:
提高程序性能、改善用户体验以及解决实际业务需求。- ①
高效利用计算资源:利用多核 CPU,提升性能并减少执行时间,如:视频渲染、大数据处理等任务分散到多个核心进行并行运算。 - ②
提高程序响应能力:避免主线程因耗时任务(如 I/O 操作)阻塞,增强用户体验,如:邮件客户端后台加载邮件内容,而用户界面不会卡顿。 - ③
提升系统吞吐量:同时处理多个任务(服务多个用户请求),增加任务完成效率,如:Web 服务器通过线程池或事件循环同时响应成千上万客户端请求。 - ④
优化等待资源时间:执行 I/O 操作时,利用 CPU 执行其他任务,减少资源闲置时间,如:网页爬取中,抓取一个网页时可以同时等待其他网络请求返回。 - ⑤
满足复杂系统需求:某些系统结构天然需要并发设计,分工协作完成任务,如:游戏开发中的渲染和物理计算分开进行,生产者-消费者模型中数据生产和消费并行处理。 - ⑥
增强可扩展性和适应未来需求:系统在更高负载需求或复杂场景下,通过扩展线程或节点资源,保持稳定运行,如:分布式计算框架(Spark、Hadoop)通过并发执行任务,能够适应大规模数据处理场景。
- ①
虽然并发编程有很多优点,但是它也伴随着一些挑战,如下所示:
- ①
复杂性增加:并发程序更难设计和调试,如:可能的死锁、竞态条件等问题。 - ②
资源消耗:线程或协程的创建和管理需要额外的资源。 - ③
不确定性:并发程序的执行顺序不可预测,导致调试和测试更加困难。 - ④
同步问题:访问共享资源时需要同步控制,稍有不慎会引入数据不一致问题。
- ①
提醒
总结:
① 使用并发编程的主要原因是为了更高效地利用硬件资源、提升性能、增强系统的交互性和响应能力,以及满足复杂任务的解决需求。通过并发编程,可以实现程序更快的运行速度、更多任务的同时执行以及面向未来的扩展能力,特别是在多核、分布式和高并发场景下,它是现代软件开发中的重要手段。
② 但是需要注意的是,并发编程带来了复杂性,实施时需要慎重考虑其带来的潜在问题,如:线程安全和资源争用。合理的设计和高效的工具,可以帮助软件开发者更好地进行并发编程。
1.2 计算机基本组成
- 计算机(Computer,电脑)是一种能够接收信息和存储信息,按照存储在其内部的程序对海量的数据进行自动、高速地处理,并将处理结果输出的现代化智能电子设备。
提醒
计算机有很多形式,如:台式电脑、笔记本电脑、智能手机、平板电脑以及各种服务器。
- 一个完整的
计算机系统由硬件(Hardware)系统和软件(Software)系统两大部分组成。
提醒
硬件和软件共同协作,硬件提供物理运行的基础,软件提供操作和处理的逻辑,计算机最终实现功能,如:数据处理、信息传递和程序执行等。

1.3 CPU
- CPU(中央处理器,Central Processing Unit)是计算机的核心组件之一,被喻为计算机的大脑。它负责执行指令、处理数据,并控制计算机内其他部件之间的操作和通信。
- CPU 的主要功能是从内存中获取指令并执行它们,根据指令完成算术或逻辑操作,以及协调其他硬件设备完成任务。
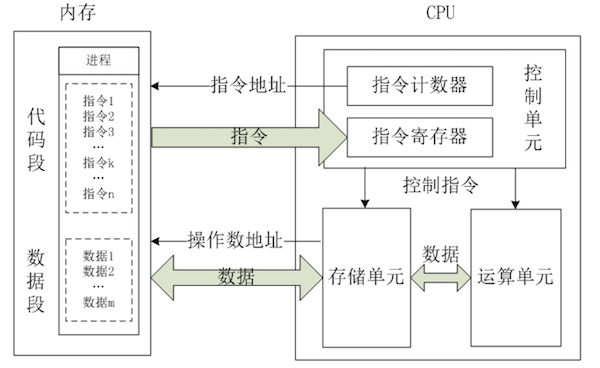
- CPU 从逻辑上可以划分为 3 个模块:控制单元(CU)、算术逻辑单元(ALU)以及存储单元(Registers)。
提醒
CPU 的运行原理:
- ① 控制单元在时序脉冲的作用下,将指令计数器里所指向的指令地址(这个地址是在内存里的)送到地址总线上去,并由 CPU 将这个地址里的指令读到指令寄存器进行译码。
- ② 对于执行指令过程中所需要用到的数据,会将数据地址也送到地址总线,然后 CPU 把数据读到 CPU 的内部存储单元(内部寄存器)暂存起来,
- ③ CPU 命令运算单元对数据进行处理加工。
- ④ 周而复始重复①②③,一直这样执行下去。
- CPU 的常见厂商,如下所示:
- 英特尔(Intel):高性能台式机和服务器 CPU,如:Intel Core i 系列、Xeon 等。
- AMD:与英特尔竞争的厂商,以 Ryzen 系列和 EPYC 系列著称,主打性价比和多核性能。
- ARM :ARM 架构 CPU 被广泛应用于移动设备,如:高通 Snapdragon、苹果 A 系列芯片。
- 苹果 M 系列:自研的 M 系列芯片,基于 ARM 架构,广泛用于 Mac 和 iPad。
- ...
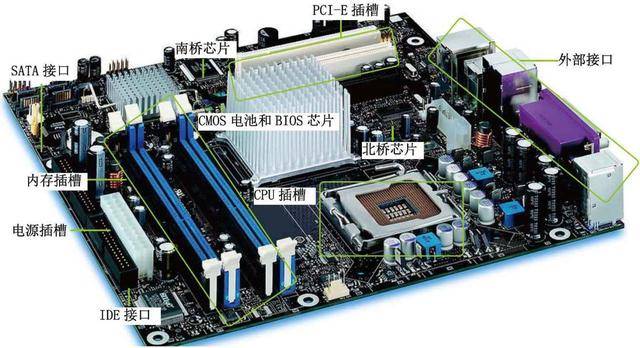
- 在微型计算机(个人计算机)中,CPU 是安装在主板上的,有正反之分:


1.4 CPU 的发展
1.4.1 概述
- 最早的计算机使用的是
真空管,像 ENIAC 这样的机器又大又笨重,它们不仅消耗大量的电力,而且还产生大量的热量。

- 20 世纪 40 年代末,
晶体管的发明彻底改变了 CPU 技术,晶体管取代了真空管,使计算机变得更小、更可靠、更节能。

- 20 世纪 60 年代中期,人们开发了集成电路 (IC),将多个晶体管和其他元件组合在一个计算机芯片上,CPU 变得更小、更快,从而使微处理器出现。

1.4.2 摩尔定律
- 1965 年,英特尔创始人之一
戈登·摩尔提出了指导半导体行业长达半实际之久的摩尔定律:“是集成电路上可容纳的元器件(晶体管)的数量每隔 18 至 24 个月就会增加一倍,性能也将提升一倍”。
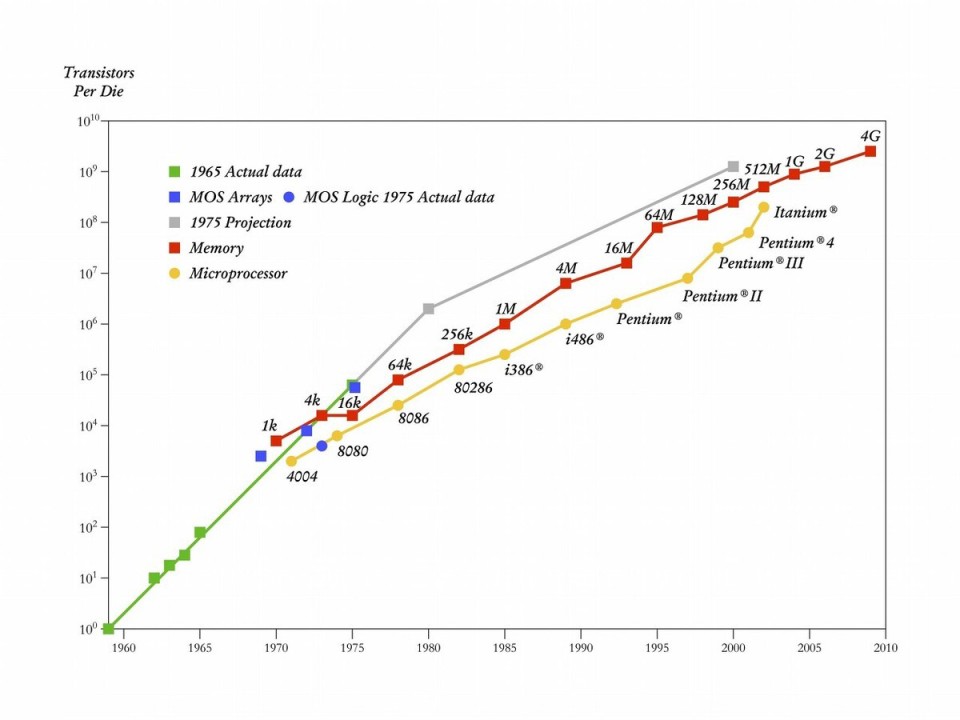
- 但是,随着晶体管密度的增加,进一步提高单核 CPU 性能变得具有挑战性,种种物理限制约束着它的进一步发展,如:当闸极长度足够短的时候,就会发生
量子穿隧效应,会导致漏电流增加。取而代之的是,CPU 制造商开始使用多核处理器架构将多个内核集成到单个芯片上。
1.4.3 单核 CPU
- 早期的 CPU 都是一个核心,即:整个处理器只能有一个
运算单元来执行所有指令。

- 早期的
单核CPU是可以运行多线程的;但是,是通过操作系统进行时间片调度造成的假象。
提醒
操作系统将时间划分为很小的一段(时间片),操作系统以时间片为单位进行调度,即:同一时刻,只有一个线程(指令流)可以在物理核上运行。

1.4.4 多 CPU
- 个人计算机上的主板上只有一个 CPU 插槽,即:只能安装有一个 CPU ,如下所示:
- 但是,服务器的主板上却有很多 CPU 插槽,即:可以安装多个 CPU ,如下所示:

多CPU中的每个 CPU 都有自己的核心,即:每个 CPU 都有一个运算单元来执行对应的指令。

多CPU是可以运行多线程的,即:同一时刻,可以执行多条指令。

1.4.5 多核 CPU
- 虽然,
多CPU可以在同一时刻,执行多条指令。但是,会有以下的问题:- ① 个人计算机只有一个 CPU 插槽,实现不了同一时刻,执行多条指令。
- ② 服务器虽然有多个 CPU 插槽,但也不能无休止的安装 CPU ,总有极限。
- 于是,出现了
多核CPU,即:一个物理 CPU 内部,封装了多个物理核心,如下所示:
提醒
- ① 每个物理核心都有自己的控制单元、存储单元以及运算单元;所以,每个物理核心都可以看成是一个
逻辑CPU。 - ② 从并行流的角度来讲,
多CPU和多核CPU都可以在同一时刻,同时执行多条指令。 - ③ 但是,
多核CPU的性能要高于多CPU,因为多核CPU内部的物理核心是通过片内总线进行通信的,速度会快于系统总线。

多核CPU是可以运行多线程的,即:同一时刻,可以执行多条指令。
提醒
- ①
多核CPU可以使得个人计算机有多个核心,如:2 核、4 核、8 核等,这样即使只有一个 CPU 插槽,也可以使得个人计算机的性能达到服务器的多CPU单核架构。 - ② 有些服务器可能有多个 CPU 插槽,在
多核CPU的技术下,可以是过去多CPU单核架构的 2 倍性能。
- 如果要构造
4个逻辑CPU的系统,其中一种方案就是使用2个物理 CPU ,每个物理 CPU 有2个物理核心。

- 如果要构造
4个逻辑CPU的系统,另外一种方案就是使用1个物理 CPU ,该物理 CPU 有4个物理核心。

1.4.6 超线程技术
超线程技术作用于物理 CPU 内部的物理核心上,其实现原理是:一个物理核心内部,会同时包含 2 份控制单元和 2 份存储单元;但是,只有 1 份运算单元。

- 在运行的时候,会有 2 条不同的指令进入
物理核心:

- 在超线程技术的作用下,一个
物理核心内部就好像有 2 个逻辑核心(逻辑 CPU ):
提醒
- ① 通常情况下,
CPU核心数和线程数是1:1的关系。 - ② 在超线程技术的影响下,
CPU核心数和线程数是1:2的关系。

- 总之,
多核CPU是硬件发展出现瓶颈后的解决方案,硬件工程师将多个 CPU 物理核心封装到同一个 CPU 中,为了加快 CPU 的速度,更是引入了超线程技术,使得CPU核心数和线程数是1:2的关系。
提醒
硬件开发人员的解决方案,导致了软件开发人员不得不面对头疼的并发编程问题,如下所示:
- 如何让多核 CPU 正确的运行?
- 多线程之间如何保证线程安全,即:保证运算结果不会出现错误。
- ...
- 这些问题都需要软件开发者来进行考虑和解决,毕竟现在早就进入了
多核CPU的时代,我们再也不能期望回到单核CPU的时代;所以,我们不得不去研究并发编程。
1.4.7 阿姆达尔定律
1.4.7.1 概述
- 多核 CPU 的出现,让我们可以采用并行处理程序;但是,并行处理程序能提升多少性能,可以使用
阿姆达尔定律来进行指导,其是计算机科学界的经验法则,代表了处理器并行运算之后效率提升的能力。
1.4.7.2 数学公式
- 阿姆达尔定律的数学公式,如下所示:
提醒
参数说明:
S表示性能加速比(Speedup),表示执行任务的处理速度的提高倍数。P表示可以并行化的任务部分的比例,即:并行部分。1 - P表示必须串行执行的任务部分的比例,即:串行部分。N表示参与并行计算的处理单元(核心)数量。
提醒
点我查看 如何理解
阿姆达尔定律的基本思想是:即便你无限增加并行处理的能力,系统性能仍然会受到任务中串行部分的制约。
- ①
串行部分的限制:即使一个程序的主要部分可以并行化;但是,如果仍然有某些部分无法并行化(必须串行执行),那么这个串行部分的占比将成为总性能提升的瓶颈。- 如果任务的串行部分占比较大,即
较大,那么整体性能提升将非常有限。 - 如果任务的串行部分占比很小,即
趋近于 0,则性能提升接近并列效率的理论理想值。
- 如果任务的串行部分占比较大,即
- ②
并行化的收益递减:随着并行化程度(N,参与计算的核心数)的增加,任务的并行部分会受到核心通信、同步等因素的影响,收益逐渐趋于平缓。理论上,无限增加核心数仍然不能无限提高性能,因为串行部分始终需要时间去完成。
- 示例:假设一个程序的 60% 的代码可以并行化,即:
,其余 40% 需要串行执行,即: ,如果我们尝试使用 2 个并行核心( ),性能提升约为 1.43 倍
- 示例:假设一个程序的 60% 的代码可以并行化,即:
,其余 40% 需要串行执行,即: ,如果我们尝试使用 4 个并行核心( ),性能提升约为 1.82 倍
1.4.7.3 应用场景
- ①
并行计算的性能分析:阿姆达尔定律为系统工程师和架构师提供了计算并行化效率和规划性能优化的方向。例如:在高性能计算(HPC)中,用于预测增加计算节点数量后的性能提升。 - ②
软件和程序优化:根据阿姆达尔定律,开发人员应更专注于减少程序中的串行部分,因为串行部分不仅直接影响程序效率,还间接降低了并行优化的收益。 - ③ 硬件划分和负载均衡:为解决性能瓶颈,阿姆达尔定律可以帮助系统设计者进行计算资源分配,如:分配更多资源给影响系统性能的串行部分。
1.4.7.4 局限性
- ①
忽略了并行化本身的开销:并行化任务的过程中,通常会引入额外的开销,如:任务分割、线程同步、通信延迟等。这些开销可能降低实际加速比。 - ②
任务规模未变化:阿姆达尔定律假设任务的规模固定(即问题大小固定),但在实际应用中,增加计算资源往往会用于处理更大规模的任务。 - ③
未考虑资源竞争:系统中的处理单元可能共享内存、I/O 设备等资源,导致资源竞争,这会进一步限制并行效率。
第二章:多线程的概念(⭐)
2.1 进程和线程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的系统中(早期的 Unix、Linux 2.4 及其之前的版本),进程是程序的基本执行实体。在当代面向线程设计的系统中(现代的操作系统,Linux 2.6 及其之后的版本),进程是线程的容器。
提醒
点我查看 详细信息
- ① Windows 资源管理器看到的都是进程,进程是操作系统管理的基本单元。
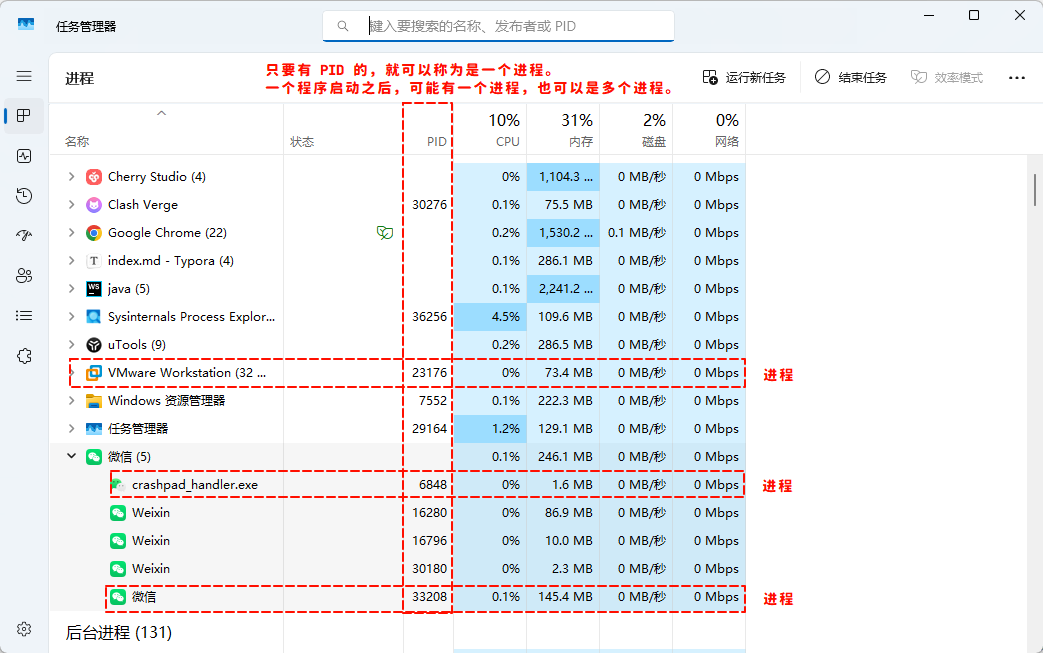
- ② Linux 中,可以使用
top、htop、glances、ps等命令查看进程,进程是操作系统管理的基本单元。
线程(Thread)是进程中独立运行的子任务,如:微信是一个进程,里面运行了很多子任务,像聊天信息发送线程、远程视频或语音会议线程、文件上传下载线程等等,这些子任务我们就理解为线程,这些线程可以同时运行,这些子任务同时运行带来的好处就是在同一时间内可以运行多种不同类型的任务。
提醒
点我查看 详细信息
- ① Windows 中查看线程信息,需要借助 Process Explorer 工具。
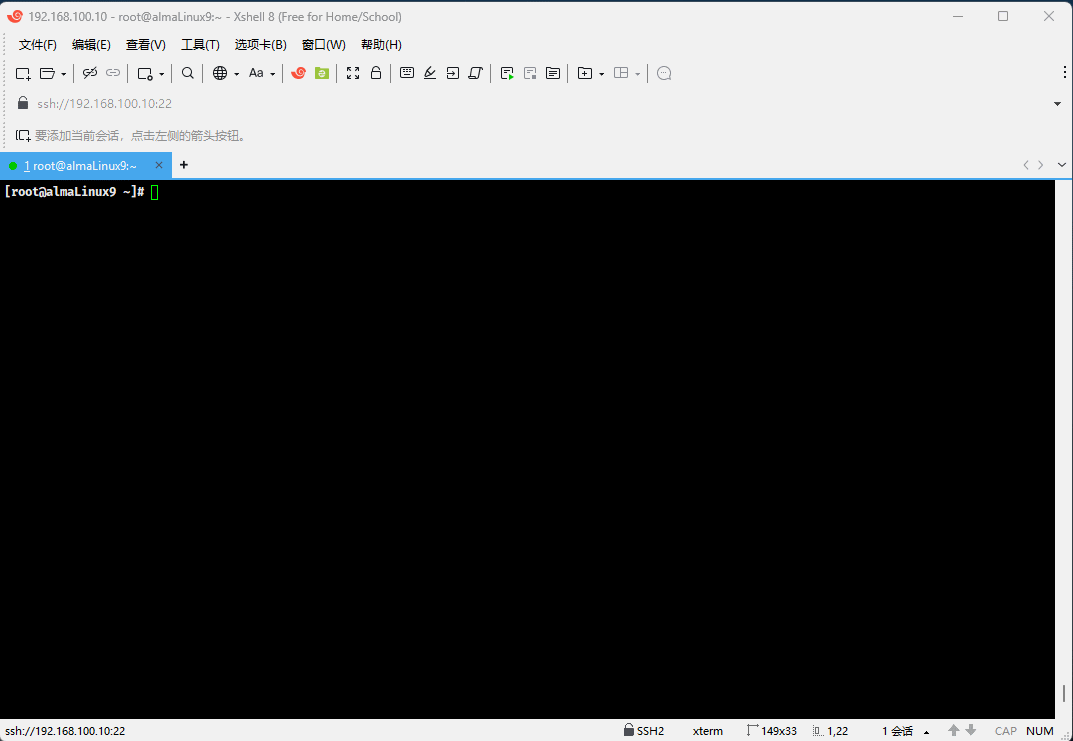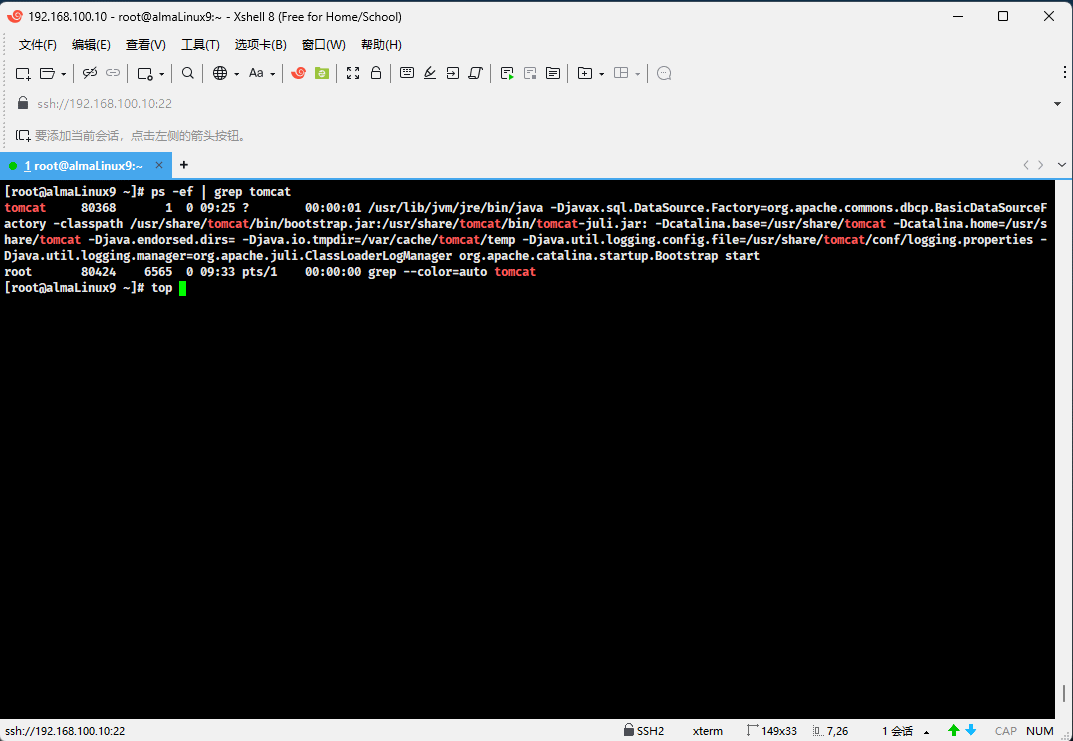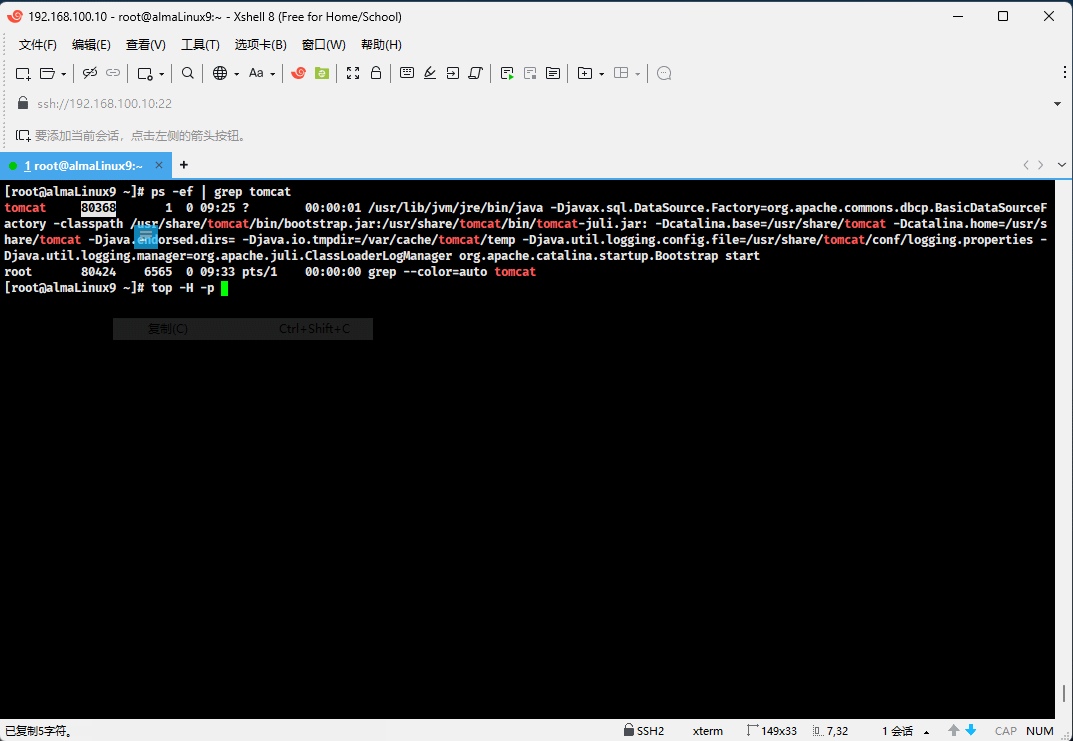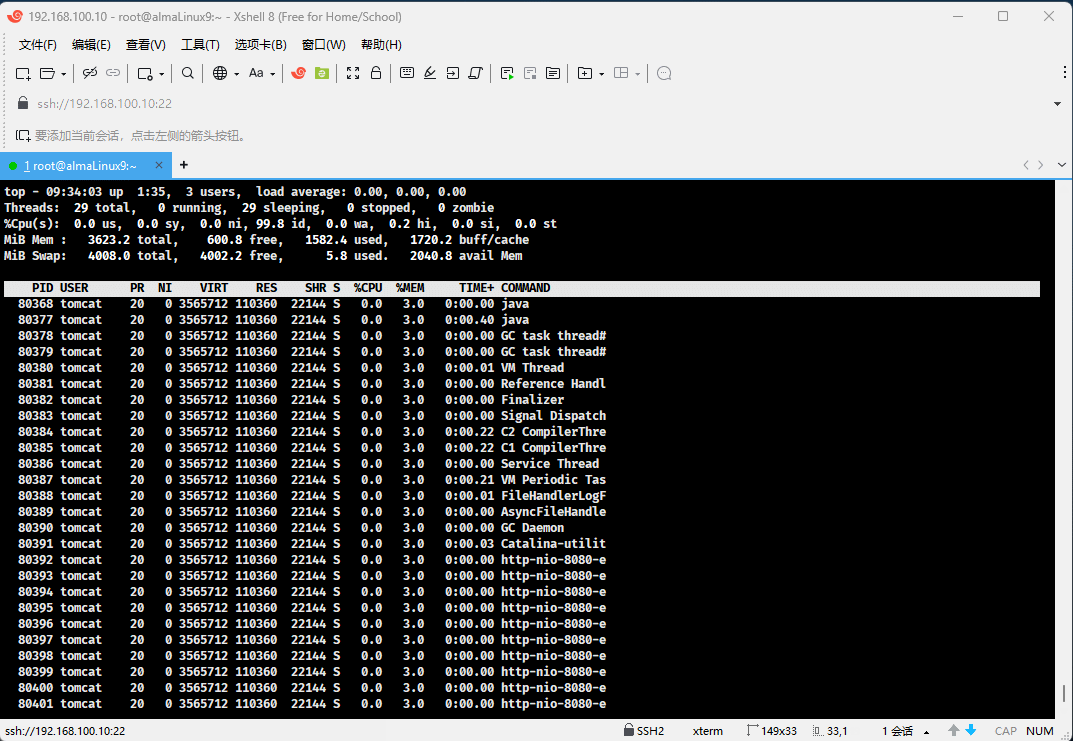
- ② Linux 中,可以使用
top -H -p <pid>、htop、glances等命令查看线程信息。
2.2 构建 OpenJDK
2.2.1 概述
- OpenJDK 是用
Java和C/C++混合编写的大型项目:Java 层:java.lang,java.util等核心类库是用 Java 写的。C/C++ 层:HotSpot 虚拟机、JNI 实现、平台相关代码等是用 C/C++ 写的。
- 当我们从源码开始构建 OpenJDK 的时候,我们需要一个 Boot JDK(引导 JDK),其作用如下:
提醒
- ① 引导 JDK 不是用来运行我们正在构建的新 JDK,而是用于辅助构建过程本身!!!
- ② 目前 OpenJDK 官方默认构建方式要求有 Boot JDK 。
| 用途 | 描述 |
|---|---|
| 编译 Java 源码 | 使用javac编译 OpenJDK 中的.java文件 |
| 运行注解处理器 | apt或annotation processing需要运行时支持 |
| 生成工具类或资源文件 | 某些构建阶段会运行 Java 程序生成.properties,.h,.c文件等 |
| 打包 JAR 文件 | 使用jar命令打包类文件和资源 |
| 运行测试工具 | 构建过程中可能运行一些验证脚本或测试程序 |
- 引导 JDK 的版本要求:
提醒
对于 JDK17 来说 ,我们需要至少一个 JDK16 或 JDK17 的环境作为引导。
| 正在构建的 JDK 版本 | 推荐使用的 Boot JDK 版本 |
|---|---|
| JDK 8 | JDK 7 或更高 |
| JDK 11 | JDK 10 或更高 |
| JDK 17 | JDK 16 或更高 |
| JDK 21 | JDK 20 或更高 |
- 而对于 C/C++ ,则需要使用 GCC 编译器来编译 C/C++ 源码。
提醒
- ① 在 Windows 操作系统中,可以使用 MSYS2 来作为构建环境,因为其支持 Linux 工具集。
- ② 在 Windows 操作系统中,也可以使用 WSL2 作为构建环境。
2.2.2 准备一台 Linux 服务器
- ① 本人在 VMWare 中安装了 AlmaLinux9 ,如下所示:
- ② 通过 XShell 远程登录 AlmaLinux9 :
- ③ 安装必要的工具:
sudo dnf update -y
sudo dnf install epel-release -y
sudo dnf groupinstall "Development Tools" -y
sudo dnf install java-17-openjdk-devel libX11-devel libXext-devel \
libXrender-devel libXtst-devel libXt-devel cups-devel git gcc \
freetype-devel alsa-lib-devel zlib-devel openssl-devel \
autoconf automake libtool python3 unzip zip java-17* \
libXtst-devel libXt-devel libXrender-devel libXrandr-devel libXi-devel \
fontconfig-devel tree -y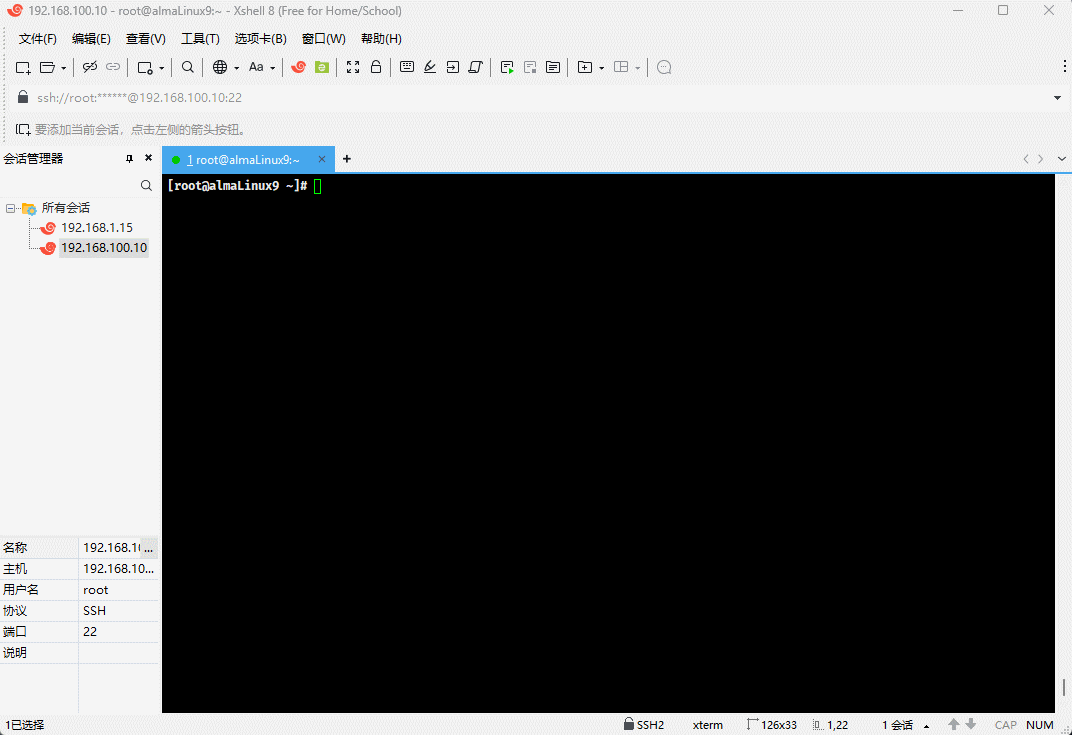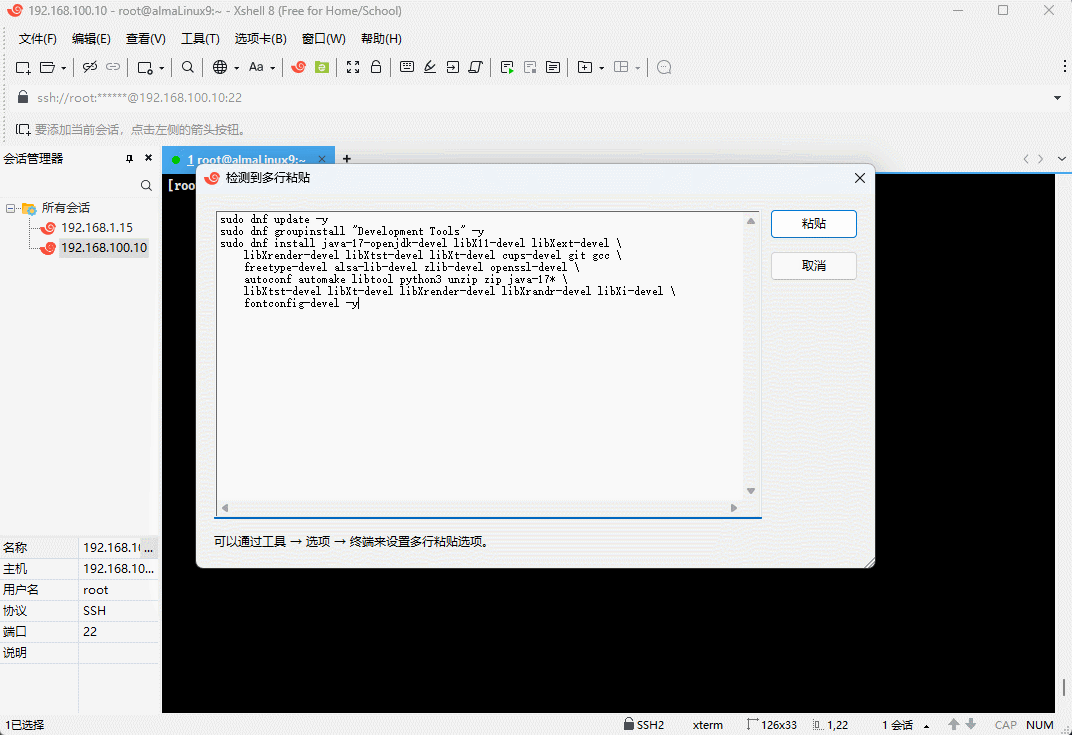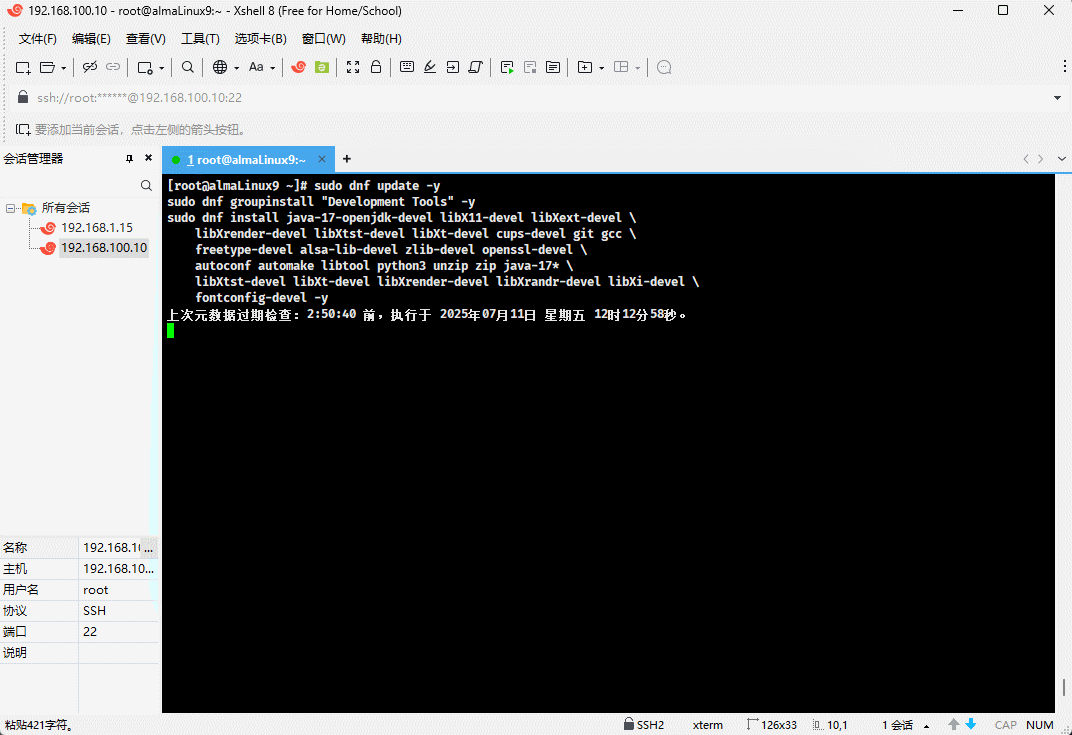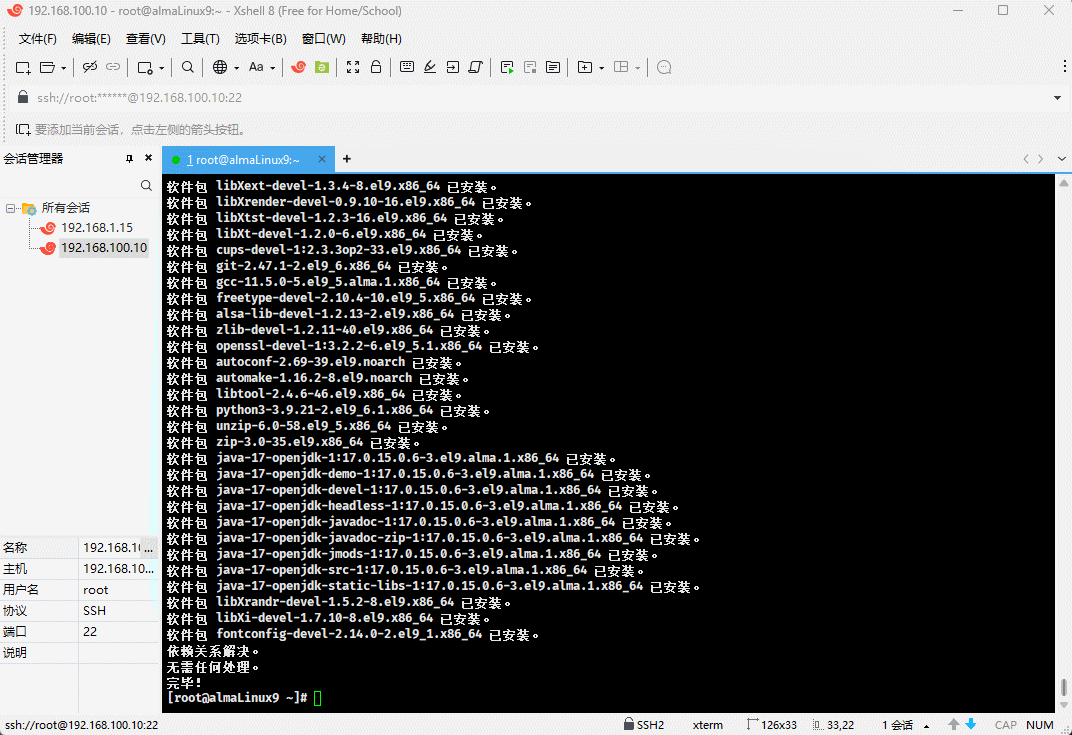
2.2.3 构建 OpenJDK
- ① 通过 Git 下载 OpenJDK 的源码:
git clone git@github.com:openjdk/jdk17u.git --depth=1
- ② 运行 configure 文件:
cd jdk17u
bash configure --with-jvm-variants=server --build=x86_64-unknown-linux-gnu
- ③ 运行 make :漫长的等待...
make images JOBS=$(nproc)
- ④ 验证新构建的 JDK :
./build/*/images/jdk/bin/java -version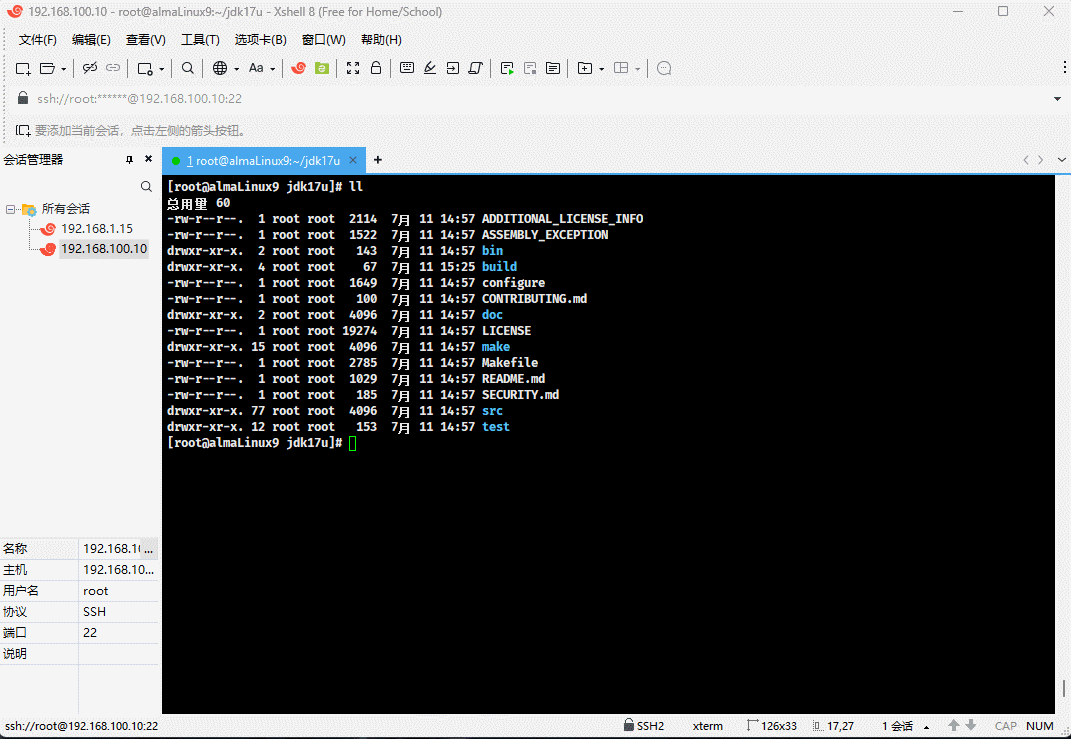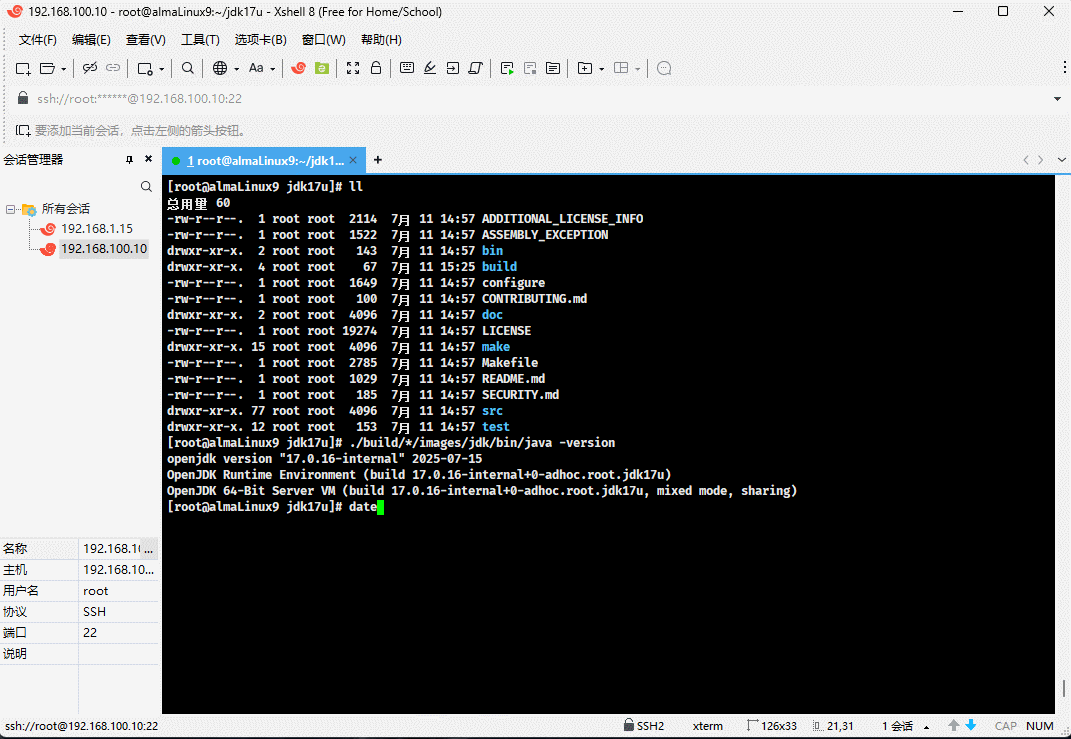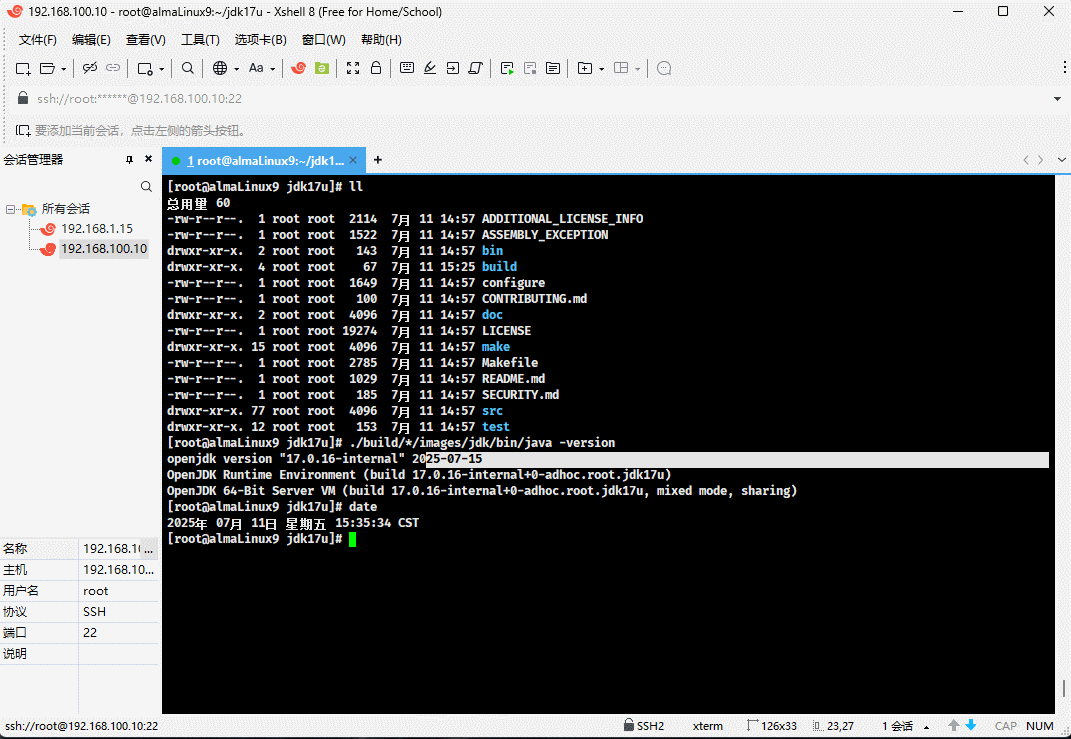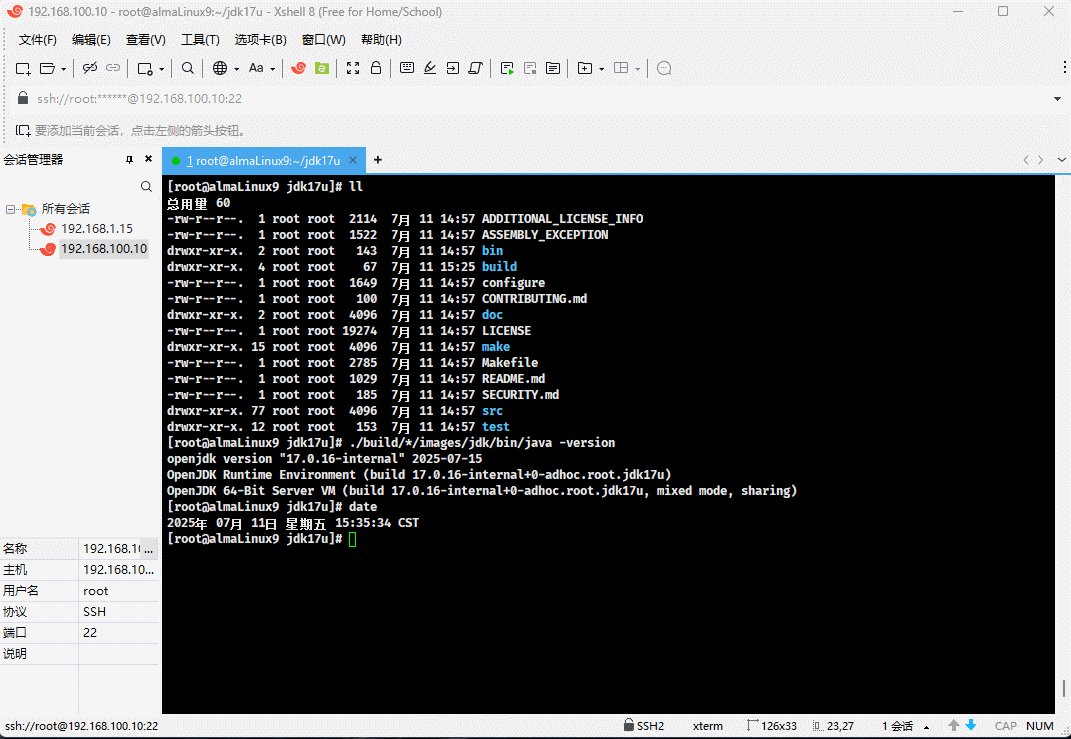
- ⑤ 运行基本测试:
make run-test-tier1
2.3 Java 创建线程的使用方式
2.3.1 概述
- Java 创建线程很多方式,如下所示:
- ①
继承 Thread 类的方式创建线程。 - ②
实现 Runnable 接口的方式创建线程。 - ③
利用 Callable 接口和 Future 接口的方式创建线程。 - ④
通过线程池的方式创建线程。 - ⑤ ...
- ①
提醒
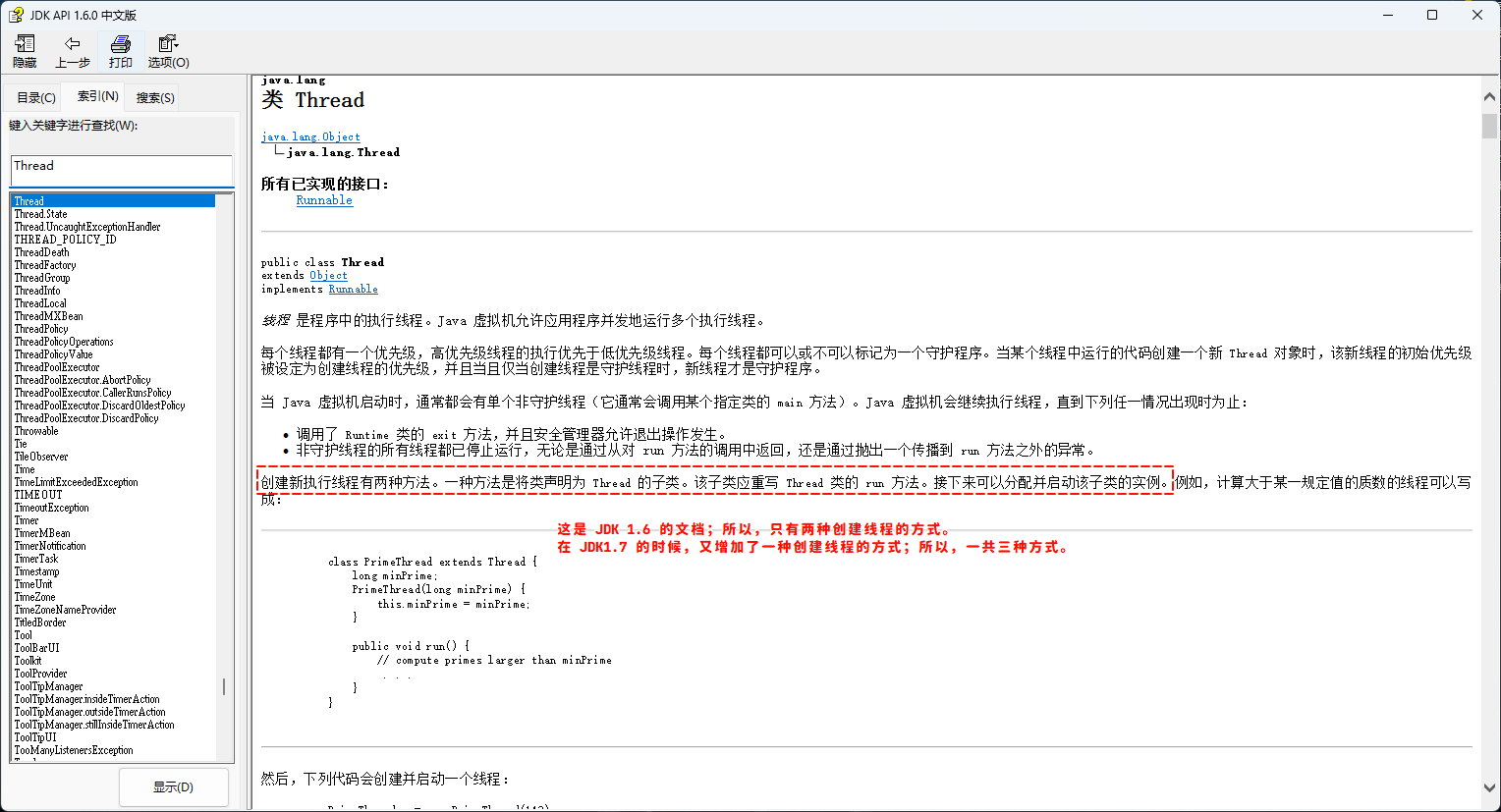
- ① 在 Java 中,Thread 类的对象就是一个线程;换言之,如果我们要创建线程,就需要继承 Thread 类,即:Thread 类的子类,并创建 Thread 子类的对象。
- ② 仅仅创建 Thread 类的子类对象还不行,因为其只是在堆内存空间中创建了对象,还需要调用 start() 方法,才会真正的创建线程。
- 但是,目前只会演示第一种方式创建线程,步骤如下:
- ①
自己定义一个类继承 Thread 类。 - ②
重写 run 方法。 - ③
创建子类的对象,调用 start() 方法启动线程。
- ①
- 其实现代码,如下所示:
package com.github.thread.demo1;
public class MyThread extends Thread {
@Override
public void run() {
final String name = Thread.currentThread().getName();
for (int i = 0; i < 100; i++) {
System.out.println(name + i);
}
}
}package com.github.thread.demo1;
public class Test {
public static void main(String[] args) {
/*
* Java 中实现线程的第一种方式:
* 1. 创建一个继承 Thread 类的子类。
* 2. 重写 run 方法,在 run 方法中编写线程的逻辑
* 3. 然后创建该子类的实例,调用 start 方法启动线程
*
* 注意:start 方法会调用 run 方法,但是 start 方法是异步执行的,run 方法是同步执行的
* 注意:run 方法中不能抛出异常,否则会导致线程终止
* 注意:run 方法中不能调用 yield 方法,否则会导致线程调度器无法调度该线程
* */
MyThread t = new MyThread();
t.start();
for (int i = 0; i < 100; i++) {
System.out.println("主线程:" + i);
}
}
}
2.3.2 面向接口编程
2.3.2.1 概述
- 在实际开发中,我们非常推崇
面向接口编程的思维方式,即:通过依赖抽象(接口)而不是具体实现,以增强代码的灵活性和可扩展性。
提醒
点我查看 生活中的例子
- 在生活中,最为常见的就是笔记本电脑上的 USB 接口了,其是一种规范,即:不同的版本有不同的要求,如:USB 2.1 、USB 3 等)。
- 如果某种设备(键盘、U 盘、鼠标等)实现了 USB 接口(USB 2.1),那么该设备就可以插入到电脑上的 USB 接口(USB 2.1)上使用。
2.3.2.2 Java 语言中面向接口编程
面向接口编程是 Java 编程中的一种设计原则,强调使用接口来定义系统中的行为规范,而不是依赖具体实现类。
提醒
其核心思想是“面向抽象,而非面向具体编程”!!!

- 示例:
// 定义 USB 接口
public interface USB {
void connect(); // 连接 USB 设备
void disconnect(); // 断开 USB 设备
}// 实现 USB 接口:键盘
public class Keyboard implements USB {
@Override
public void connect() {
System.out.println("Keyboard connected.");
}
@Override
public void disconnect() {
System.out.println("Keyboard disconnected.");
}
}// 实现 USB 接口:U盘
public class FlashDrive implements USB {
@Override
public void connect() {
System.out.println("FlashDrive connected.");
}
@Override
public void disconnect() {
System.out.println("FlashDrive disconnected.");
}
}// 模拟电脑类
public class Computer {
// 模拟插入 USB 设备
public void plugInUSB(USB device) {
device.connect(); // 调用设备的 connect 方法
}
// 模拟拔出 USB 设备
public void unplugUSB(USB device) {
device.disconnect(); // 调用设备的 disconnect 方法
}
}// 测试类
public class Test {
public static void main(String[] args) {
Computer computer = new Computer();
// 创建键盘设备
USB keyboard = new Keyboard();
computer.plugInUSB(keyboard); // 连接键盘
computer.unplugUSB(keyboard); // 断开键盘
System.out.println();
// 创建 U盘设备
USB flashDrive = new FlashDrive();
computer.plugInUSB(flashDrive); // 连接 U盘
computer.unplugUSB(flashDrive); // 断开 U盘
}
}2.3.2.3 C 语言中的面向接口编程
- 在 C 语言中,并没有
interface等关键字。但是,在 C 语言中,头文件就是一个接口。
├─📁 include/---- # 头文件目录
│ └─📄 add.h
├─📁 module/----- # 函数实现目录
│ └─📄 add.c
└─📄 main.c------ # 主函数
- 示例:
#ifndef ADD_H
#define ADD_H
// 函数原型
int add(int a, int b);
#endif // ADD_H#include "./include/add.h" // 导入自定义函数的头文件
// 函数声明或函数实现
int add(int a,int b) {
return a + b;
}#include <stdio.h> // 导入标准库函数的头文件
#include "./include/add.h" // 导入自定义函数的头文件
int main() {
int a = 5;
int b = 10;
int result = add(a, b);
printf("%d + %d = %d\n", a, b, result);
return 0;
}2.3.3 Java 底层是如何创建线程的?
2.3.3.1 概述
- Java 本身并没有实现线程,我们可以通过源码证明:
提醒
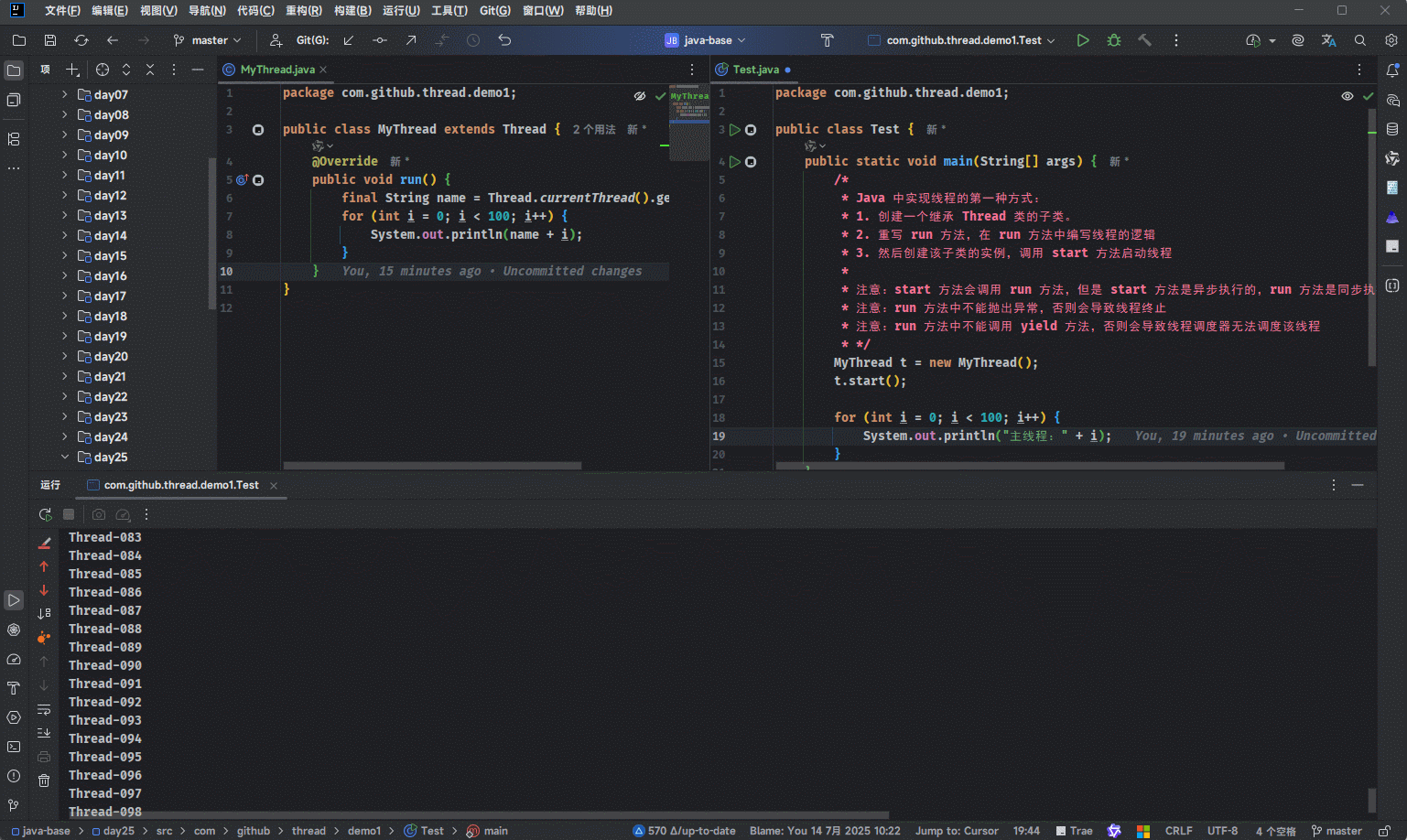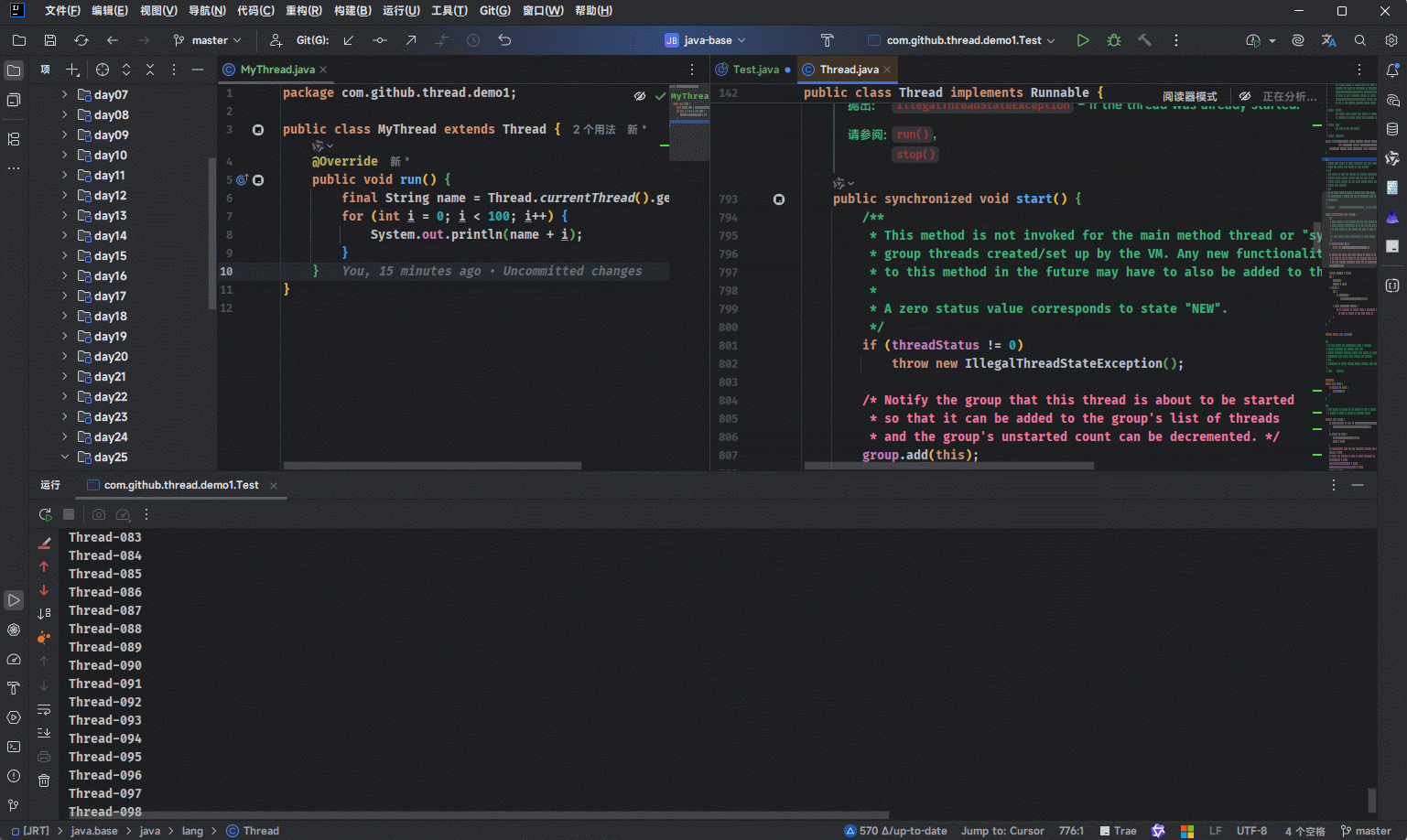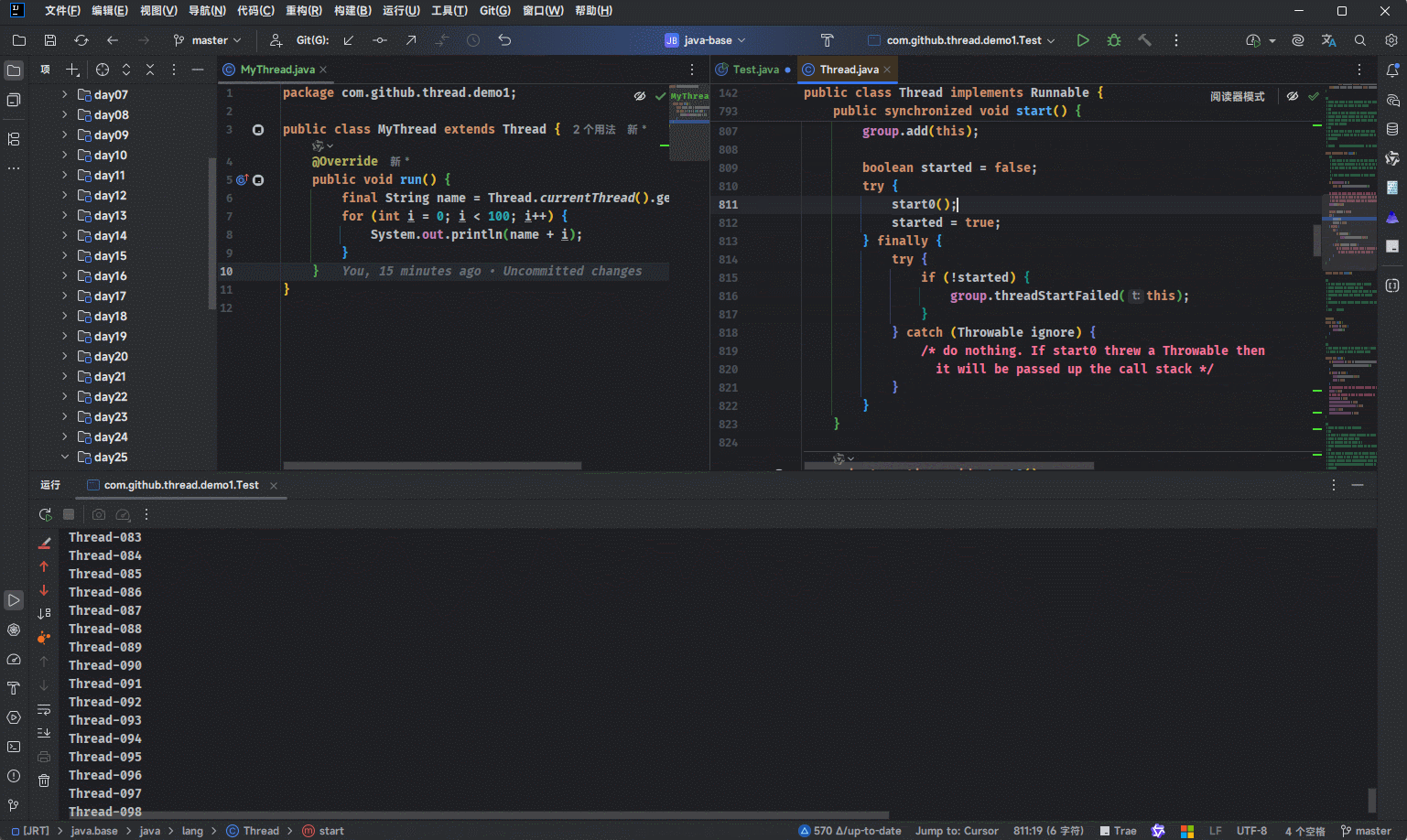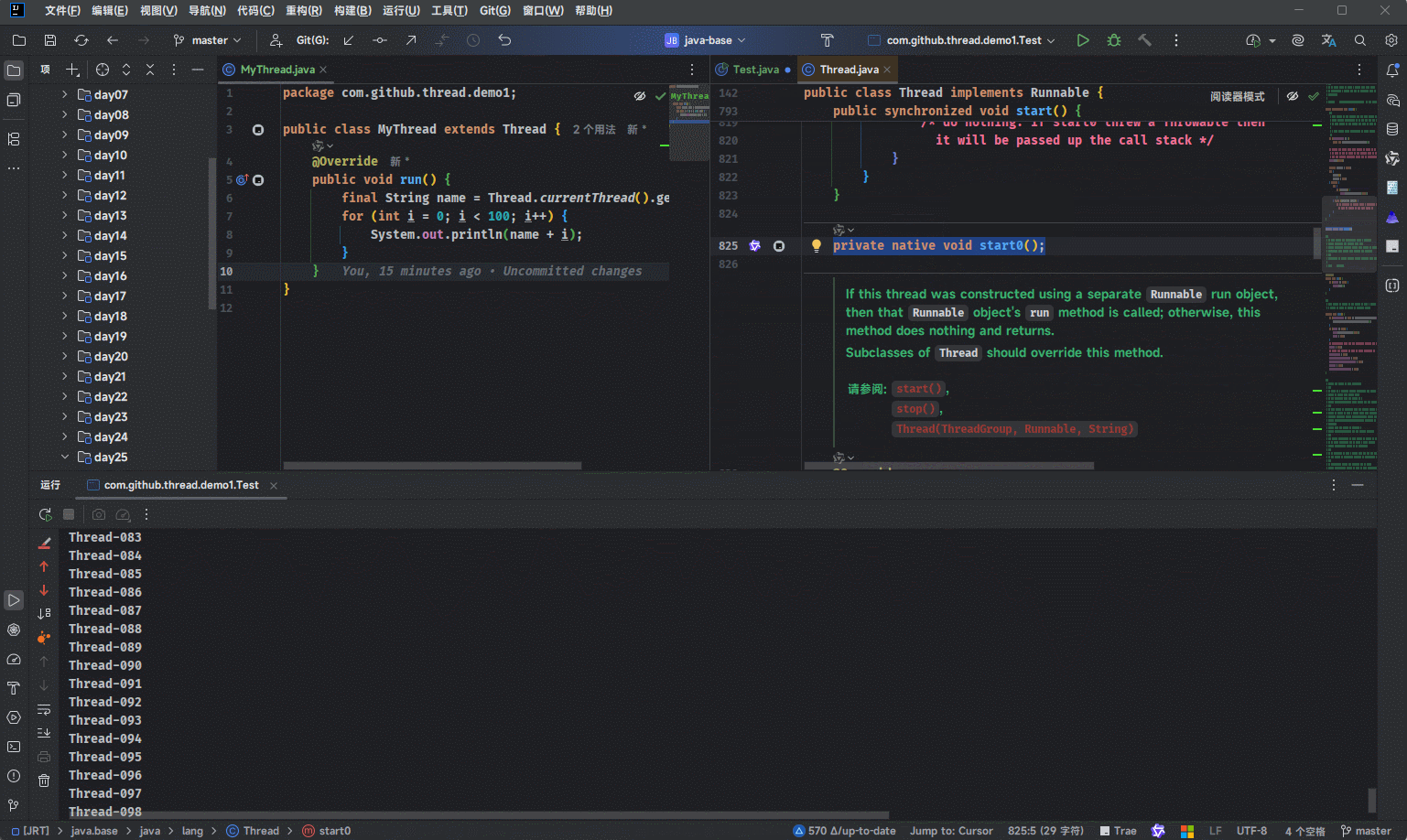
- ① 当我们通过 Thread 的子类对象,调用
start()方法的时候,其内部是调用了start0这个方法。 - ②
start0这个方法的定义是这样的:private native void start0();,该方法是一个本地方法,并且没有具体的实现。
- 对于 Windows/Linux/MacOS 而言,其系统编程语言是 C/C++,这些编程语言是可以直接调用操作系统提供的 API ,因为这些操作系统本身就是通过 C/C++ 开发的;所以,提供 C/C++ 的 API 是理所当然的事情。
提醒
- ① 近年来,Rust、Swift 有望进入系统编程语言的行列。
- ② 在 Linux 中,对于线程提供的 API 是
pthread.h头文件。
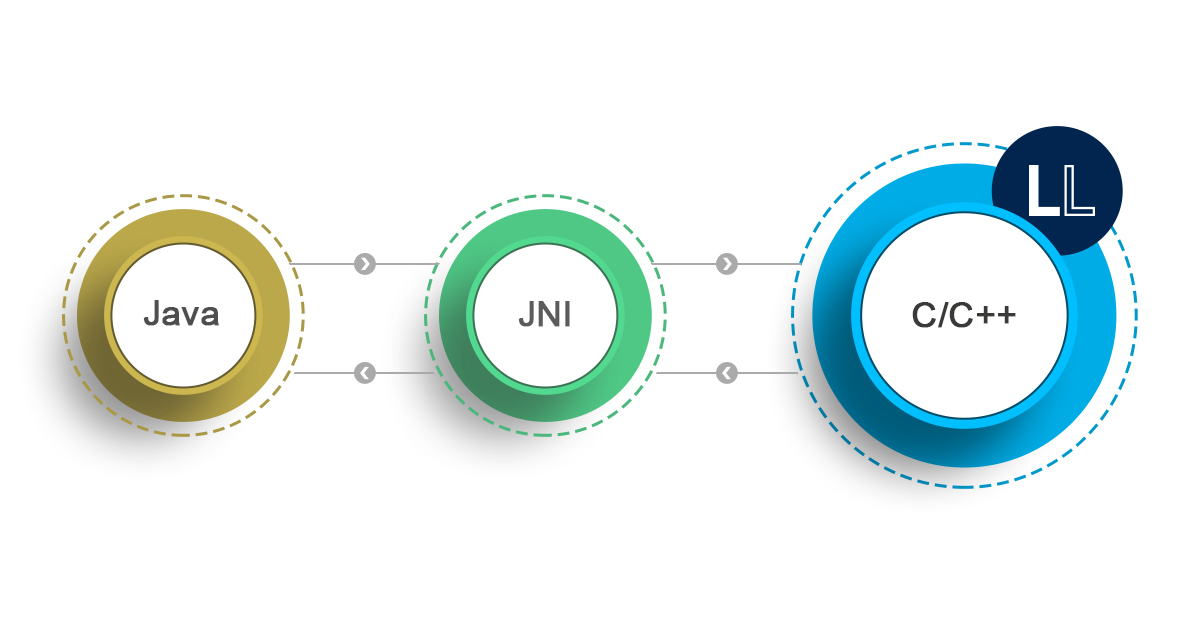
- 对于 Java 语言而言,其底层是没有实现线程的,这也是
start0方法是一个本地方法的原因,即:底层是通过 JNI 来调用操作系统提供的 C/C++ 的 API 接口,即:pthread.h头文件。
提醒
Java 本身并不创建线程,而是通过操作系统的库函数创建线程!!!
- 之前,在构建自己的 OpenJDK 的时候,我们提及过:
提醒
OpenJDK 是用 Java 和 C/C++ 混合编写的大型项目:
Java 层:java.lang,java.util等核心类库是用 Java 写的。C/C++ 层:HotSpot 虚拟机、JNI 实现、平台相关代码等是用 C/C++ 写的。
- 此时,我们将 OpenJDK 的源码导入到 CLion 中,来研究 Java 底层是否自己创建了线程:
2.3.3.2 Java 创建线程的底层分析
- 当我们在 Java 代码中,这样创建线程线程的时候,如下所示:
MyThread t = new MyThread();
t.start();- 在 Java 底层,最终会调用
start0本地方法,如下所示:
public class Thread implements Runnable {
...
public synchronized void start() {
if (threadStatus != 0)
throw new IllegalThreadStateException();
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
}
}
}
private native void start0();
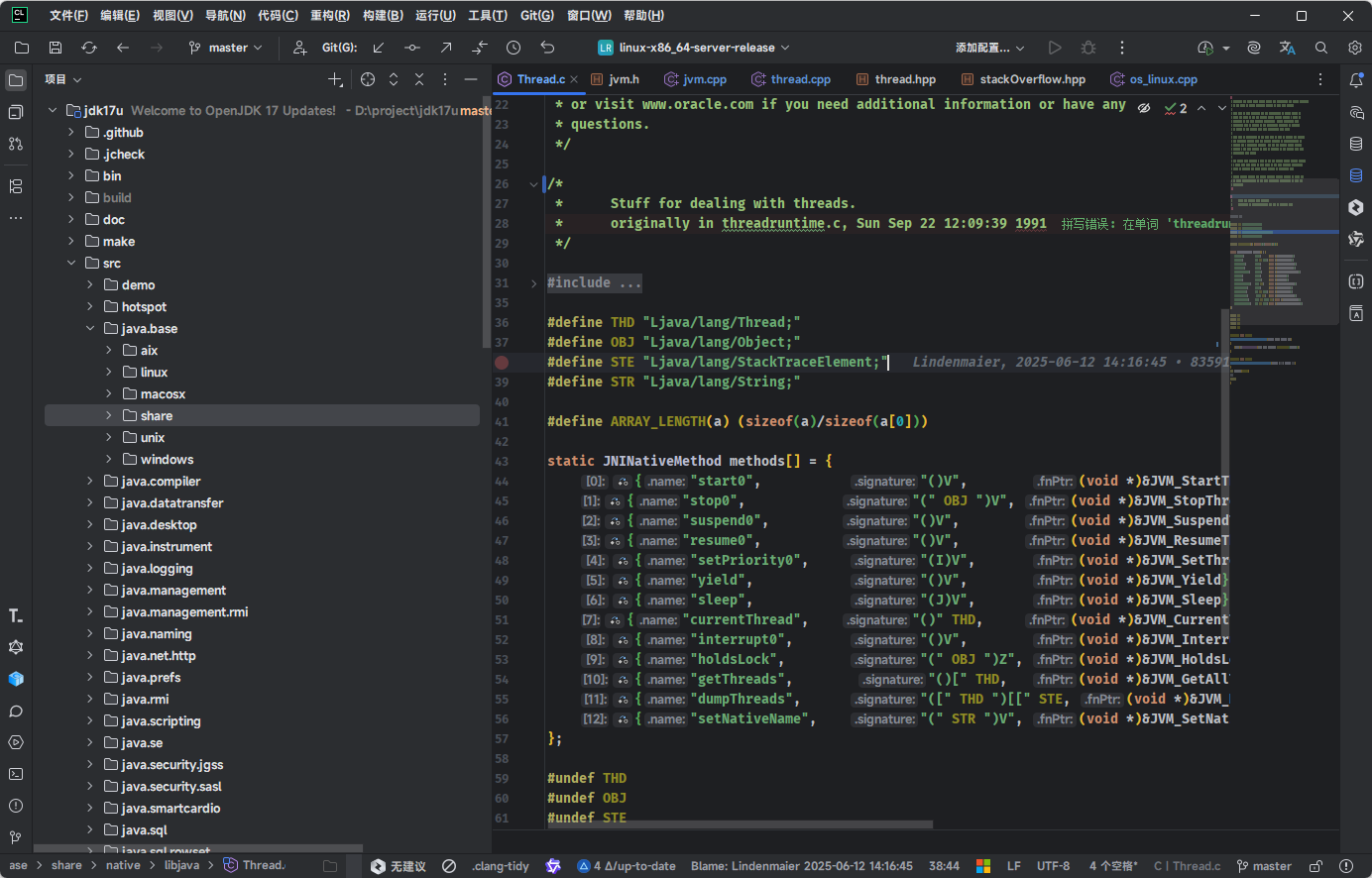
}- 在 CLion 中的完整调用流程示意图,如下所示:

start0是个本地方法,其方法的实现体是由 C 来实现的(其源码是Thread.c),如下所示:
#define THD "Ljava/lang/Thread;"
#define OBJ "Ljava/lang/Object;"
#define STE "Ljava/lang/StackTraceElement;"
#define STR "Ljava/lang/String;"
#define ARRAY_LENGTH(a) (sizeof(a)/sizeof(a[0]))
static JNINativeMethod methods[] = {
{"start0", "()V", (void *)&JVM_StartThread},
{"stop0", "(" OBJ ")V", (void *)&JVM_StopThread},
{"suspend0", "()V", (void *)&JVM_SuspendThread},
{"resume0", "()V", (void *)&JVM_ResumeThread},
{"setPriority0", "(I)V", (void *)&JVM_SetThreadPriority},
{"yield", "()V", (void *)&JVM_Yield},
{"sleep", "(J)V", (void *)&JVM_Sleep},
{"currentThread", "()" THD, (void *)&JVM_CurrentThread},
{"interrupt0", "()V", (void *)&JVM_Interrupt},
{"holdsLock", "(" OBJ ")Z", (void *)&JVM_HoldsLock},
{"getThreads", "()[" THD, (void *)&JVM_GetAllThreads},
{"dumpThreads", "([" THD ")[[" STE, (void *)&JVM_DumpThreads},
{"setNativeName", "(" STR ")V", (void *)&JVM_SetNativeThreadName},
};
...- 我们点击
JVM_StartThread的时候,会发现其跳转到jvm.h头文件:
提醒
C 语言中的头文件类似于 Java 中的接口!!!
...
JNIEXPORT void JNICALL
JVM_StartThread(JNIEnv *env, jobject thread);
...- 既然跳转到
jvm.h头文件,必须有对应的函数实现jvm.cpp:
...
JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread))
JavaThread *native_thread = NULL;
bool throw_illegal_thread_state = false;
{
MutexLocker mu(Threads_lock);
if (java_lang_Thread::thread(JNIHandles::resolve_non_null(jthread)) != NULL) {
throw_illegal_thread_state = true;
} else {
jlong size =
java_lang_Thread::stackSize(JNIHandles::resolve_non_null(jthread));
NOT_LP64(if (size > SIZE_MAX) size = SIZE_MAX;)
size_t sz = size > 0 ? (size_t) size : 0;
// 创建本地线程
native_thread = new JavaThread(&thread_entry, sz);
if (native_thread->osthread() != NULL) {
native_thread->prepare(jthread);
}
}
}
if (throw_illegal_thread_state) {
THROW(vmSymbols::java_lang_IllegalThreadStateException());
}
assert(native_thread != NULL, "Starting null thread?");
if (native_thread->osthread() == NULL) {
ResourceMark rm(thread);
log_warning(os, thread)("Failed to start the native thread for java.lang.Thread \"%s\"",
JavaThread::name_for(JNIHandles::resolve_non_null(jthread)));
// No one should hold a reference to the 'native_thread'.
native_thread->smr_delete();
if (JvmtiExport::should_post_resource_exhausted()) {
JvmtiExport::post_resource_exhausted(
JVMTI_RESOURCE_EXHAUSTED_OOM_ERROR | JVMTI_RESOURCE_EXHAUSTED_THREADS,
os::native_thread_creation_failed_msg());
}
THROW_MSG(vmSymbols::java_lang_OutOfMemoryError(),
os::native_thread_creation_failed_msg());
}
#if INCLUDE_JFR
if (Jfr::is_recording() && EventThreadStart::is_enabled() &&
EventThreadStart::is_stacktrace_enabled()) {
JfrThreadLocal* tl = native_thread->jfr_thread_local();
// skip Thread.start() and Thread.start0()
tl->set_cached_stack_trace_id(JfrStackTraceRepository::record(thread, 2));
}
#endif
Thread::start(native_thread);
JVM_END
...- 点击
native_thread = new JavaThread(&thread_entry, sz);的时候,会跳转到thread.cpp中:
...
JavaThread::JavaThread(ThreadFunction entry_point, size_t stack_sz) : JavaThread() {
_jni_attach_state = _not_attaching_via_jni;
set_entry_point(entry_point);
// Create the native thread itself.
// %note runtime_23
os::ThreadType thr_type = os::java_thread;
thr_type = entry_point == &CompilerThread::thread_entry ? os::compiler_thread :
os::java_thread;
// 创建操作系统线程
os::create_thread(this, thr_type, stack_sz);
}
...- 点击
os::create_thread(this, thr_type, stack_sz);的时候,会跳转到os_linux.cpp中:
...
bool os::create_thread(Thread* thread, ThreadType thr_type,
size_t req_stack_size) {
assert(thread->osthread() == NULL, "caller responsible");
// Allocate the OSThread object
OSThread* osthread = new OSThread(NULL, NULL);
if (osthread == NULL) {
return false;
}
// set the correct thread state
osthread->set_thread_type(thr_type);
// Initial state is ALLOCATED but not INITIALIZED
osthread->set_state(ALLOCATED);
thread->set_osthread(osthread);
// init thread attributes
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
size_t stack_size = os::Posix::get_initial_stack_size(thr_type, req_stack_size);
size_t guard_size = os::Linux::default_guard_size(thr_type);
pthread_attr_setguardsize(&attr, guard_size);
size_t stack_adjust_size = 0;
if (AdjustStackSizeForTLS) {
// Adjust the stack_size for on-stack TLS - see get_static_tls_area_size().
stack_adjust_size += get_static_tls_area_size(&attr);
} else if (os::Linux::adjustStackSizeForGuardPages()) {
stack_adjust_size += guard_size;
}
stack_adjust_size = align_up(stack_adjust_size, os::vm_page_size());
if (stack_size <= SIZE_MAX - stack_adjust_size) {
stack_size += stack_adjust_size;
}
assert(is_aligned(stack_size, os::vm_page_size()), "stack_size not aligned");
if (THPStackMitigation) {
if (HugePages::thp_pagesize() > 0 &&
is_aligned(stack_size, HugePages::thp_pagesize())) {
stack_size += os::vm_page_size();
}
}
int status = pthread_attr_setstacksize(&attr, stack_size);
if (status != 0) {
assert_status(status == EINVAL, status, "pthread_attr_setstacksize");
log_warning(os, thread)("The %sthread stack size specified is invalid: " SIZE_FORMAT "k",
(thr_type == compiler_thread) ? "compiler " : ((thr_type == java_thread) ? "" : "VM "),
stack_size / K);
thread->set_osthread(NULL);
delete osthread;
return false;
}
ThreadState state;
{
ResourceMark rm;
pthread_t tid;
int ret = 0;
int limit = 3;
do {
// 调用 Linux 系统的线程创建函数,创建线程,调用线程执行的方法是thread_native_entry,参数是 thread
ret = pthread_create(&tid, &attr, (void* (*)(void*)) thread_native_entry, thread);
} while (ret == EAGAIN && limit-- > 0);
char buf[64];
if (ret == 0) {
log_info(os, thread)("Thread \"%s\" started (pthread id: " UINTX_FORMAT ", attributes: %s). ",
thread->name(), (uintx) tid, os::Posix::describe_pthread_attr(buf, sizeof(buf), &attr));
// Print current timer slack if override is enabled and timer slack value is available.
// Avoid calling prctl otherwise for extra safety.
if (TimerSlack >= 0) {
int slack = prctl(PR_GET_TIMERSLACK);
if (slack >= 0) {
log_info(os, thread)("Thread \"%s\" (pthread id: " UINTX_FORMAT ") timer slack: %dns",
thread->name(), (uintx) tid, slack);
}
}
} else {
log_warning(os, thread)("Failed to start thread \"%s\" - pthread_create failed (%s) for attributes: %s.",
thread->name(), os::errno_name(ret), os::Posix::describe_pthread_attr(buf, sizeof(buf), &attr));
// Log some OS information which might explain why creating the thread failed.
log_info(os, thread)("Number of threads approx. running in the VM: %d", Threads::number_of_threads());
LogStream st(Log(os, thread)::info());
os::Posix::print_rlimit_info(&st);
os::print_memory_info(&st);
os::Linux::print_proc_sys_info(&st);
os::Linux::print_container_info(&st);
}
pthread_attr_destroy(&attr);
if (ret != 0) {
// Need to clean up stuff we've allocated so far
thread->set_osthread(NULL);
delete osthread;
return false;
}
// Store pthread info into the OSThread
osthread->set_pthread_id(tid);
// Wait until child thread is either initialized or aborted
{
Monitor* sync_with_child = osthread->startThread_lock();
MutexLocker ml(sync_with_child, Mutex::_no_safepoint_check_flag);
while ((state = osthread->get_state()) == ALLOCATED) {
sync_with_child->wait_without_safepoint_check();
}
}
}
// The thread is returned suspended (in state INITIALIZED),
// and is started higher up in the call chain
assert(state == INITIALIZED, "race condition");
return true;
}
...pthread_create是 Linux 系统的线程创建函数,如下所示:
- 在调用 Linux 线程库函数创建线程的同时,还执行了
thread_native_entry函数:
...
static void *thread_native_entry(Thread *thread) {
thread->record_stack_base_and_size();
#ifndef __GLIBC__
// Try to randomize the cache line index of hot stack frames.
// This helps when threads of the same stack traces evict each other's
// cache lines. The threads can be either from the same JVM instance, or
// from different JVM instances. The benefit is especially true for
// processors with hyperthreading technology.
// This code is not needed anymore in glibc because it has MULTI_PAGE_ALIASING
// and we did not see any degradation in performance without `alloca()`.
static int counter = 0;
int pid = os::current_process_id();
int random = ((pid ^ counter++) & 7) * 128;
void *stackmem = alloca(random != 0 ? random : 1); // ensure we allocate > 0
// Ensure the alloca result is used in a way that prevents the compiler from eliding it.
*(char *)stackmem = 1;
#endif
thread->initialize_thread_current();
OSThread* osthread = thread->osthread();
Monitor* sync = osthread->startThread_lock();
osthread->set_thread_id(os::current_thread_id());
if (UseNUMA) {
int lgrp_id = os::numa_get_group_id();
if (lgrp_id != -1) {
thread->set_lgrp_id(lgrp_id);
}
}
// initialize signal mask for this thread
PosixSignals::hotspot_sigmask(thread);
// initialize floating point control register
os::Linux::init_thread_fpu_state();
// handshaking with parent thread
{
MutexLocker ml(sync, Mutex::_no_safepoint_check_flag);
// notify parent thread
osthread->set_state(INITIALIZED);
sync->notify_all();
// wait until os::start_thread()
while (osthread->get_state() == INITIALIZED) {
sync->wait_without_safepoint_check();
}
}
log_info(os, thread)("Thread is alive (tid: " UINTX_FORMAT ", pthread id: " UINTX_FORMAT ").",
os::current_thread_id(), (uintx) pthread_self());
assert(osthread->pthread_id() != 0, "pthread_id was not set as expected");
if (DelayThreadStartALot) {
os::naked_short_sleep(100);
}
// call one more level start routine
// TODO run 方法
thread->call_run();
// Note: at this point the thread object may already have deleted itself.
// Prevent dereferencing it from here on out.
thread = NULL;
log_info(os, thread)("Thread finished (tid: " UINTX_FORMAT ", pthread id: " UINTX_FORMAT ").",
os::current_thread_id(), (uintx) pthread_self());
return 0;
}
...- 最终执行了
thread->call_run();,如下所示:
...
void Thread::call_run() {
DEBUG_ONLY(_run_state = CALL_RUN;)
// At this point, Thread object should be fully initialized and
// Thread::current() should be set.
assert(Thread::current_or_null() != NULL, "current thread is unset");
assert(Thread::current_or_null() == this, "current thread is wrong");
// Perform common initialization actions
MACOS_AARCH64_ONLY(this->init_wx());
register_thread_stack_with_NMT();
JFR_ONLY(Jfr::on_thread_start(this);)
log_debug(os, thread)("Thread " UINTX_FORMAT " stack dimensions: "
PTR_FORMAT "-" PTR_FORMAT " (" SIZE_FORMAT "k).",
os::current_thread_id(), p2i(stack_end()),
p2i(stack_base()), stack_size()/1024);
// Perform <ChildClass> initialization actions
DEBUG_ONLY(_run_state = PRE_RUN;)
this->pre_run();
// Invoke <ChildClass>::run()
DEBUG_ONLY(_run_state = RUN;)
// 调用了 run 方法中的代码
this->run(); // [!dode highlight]
// Returned from <ChildClass>::run(). Thread finished.
// Perform common tear-down actions
assert(Thread::current_or_null() != NULL, "current thread is unset");
assert(Thread::current_or_null() == this, "current thread is wrong");
// Perform <ChildClass> tear-down actions
DEBUG_ONLY(_run_state = POST_RUN;)
this->post_run();
// Note: at this point the thread object may already have deleted itself,
// so from here on do not dereference *this*. Not all thread types currently
// delete themselves when they terminate. But no thread should ever be deleted
// asynchronously with respect to its termination - that is what _run_state can
// be used to check.
assert(Thread::current_or_null() == NULL, "current thread still present");
}
...2.4 线程有哪些实现方式?
2.4.1 概述
- 线程的实现方式主要有如下的三种方式:
- ① 内核线程实现。
- ② 用户线程实现。
- ③ 用户线程 + 内核线程混合实现。
2.4.2 内核线程
2.4.2.1 概述
- 内核线程(Kernel-Level Thread,KLT)是直接由操作系统内核(kernel)支持的线程。
提醒
- ① 内核线程是由操作系统内核来完成线程切换,操作系统内核通过操纵调度器(Scheduler)对线程进行调度,并负责将线程的任务映射到各个处理器上。
- ② 程序一般不会直接使用内核线程,而是使用它的高级接口:
轻量级进程(LWP)。轻量级进程就是我们通常意义上讲的线程。每个轻量级进程都由一个内核线程支持,这种方式称为 1:1 的线程模型。 - ③ Java 中的线程就是采用内核线程的方式实现的(JDK21 之前的版本)。
- ④ JDK21 之后,Java 正式推出了虚拟线程,其就不再是采用内核线程的方式实现!!!

- 优点:一个线程阻塞,并不会影响到另一个线程的执行。
- 缺点:
- 由于是基于内核线程实现,各种线程操作,如:创建、休眠、同步等,都需要进行系统调用,而系统调用的代价相对较高,即:需要在用户态和系统内核态之间频繁切换,影响性能。
- 操作系统内核支持的线程数量是有限的,不可能无限地创建线程。
2.4.2.2 Linux 内核支持的最大线程数
2.4.2.2.1 通过文件查询(系统级别)
- 查询 Linux 内核支持的最大线程数(系统级别):
cat /proc/sys/kernel/threads-max
2.4.2.2.2 通过命令查询(系统级别)
- sysctl 可以在运行时修改或查看内核参数:
sysctl [-w][-a] [[k]=v] [...]sysctl -p [file]提醒
① sysctl 命令用于在运行时修改内核参数。可用的参数为 “/proc/sys/” 下列出的参数。
-a:表示输出所有的内核参数。
-w k=v :临时修改指定的内核参数。
[k]:表示输出指定的内核参数,格式为
目录.文件,如:threads.max。
② sysctl 的配置文件是 /etc/sysctl.conf,可以在其中配置内核参数,系统重启时会自动加载,即:永久修改。
- -p [file]:手动加载配置文件,让其生效。
- 示例:查询 Linux 内核支持的最大线程数
sysctl kernel.threads-max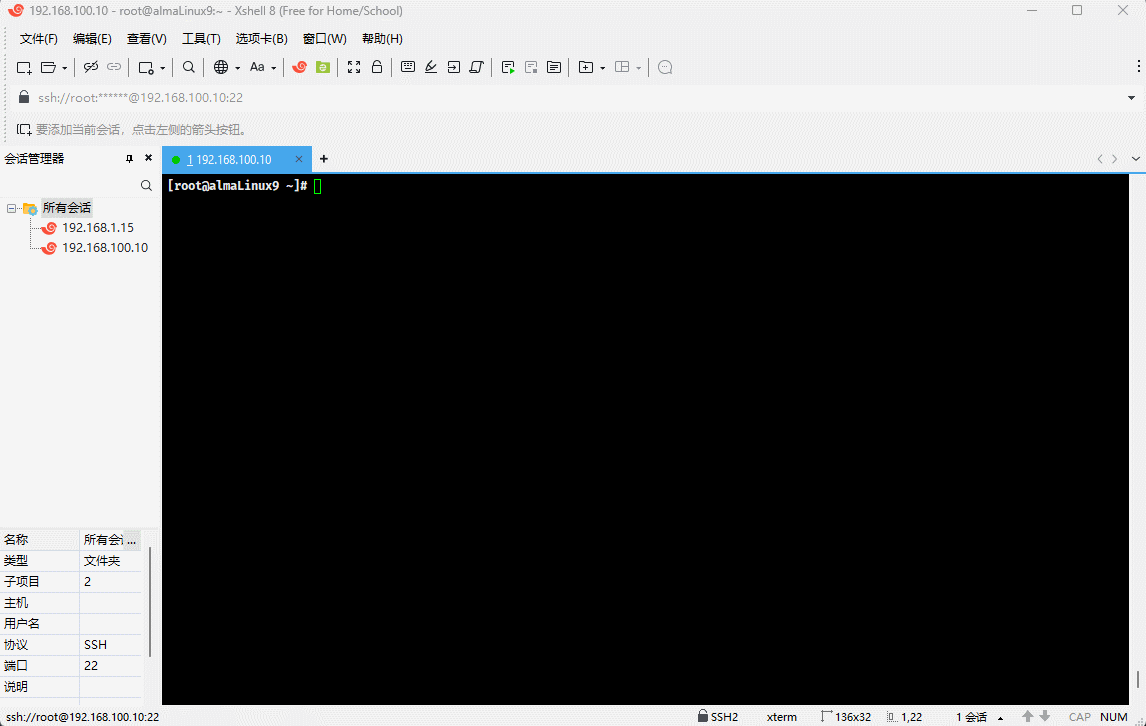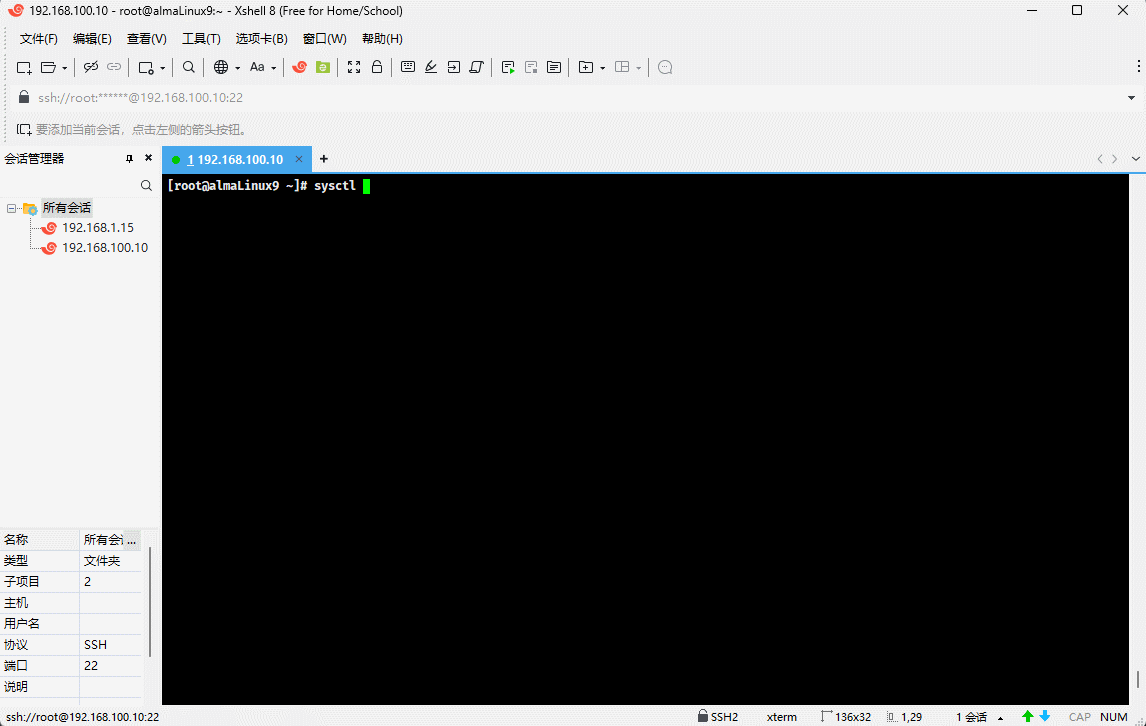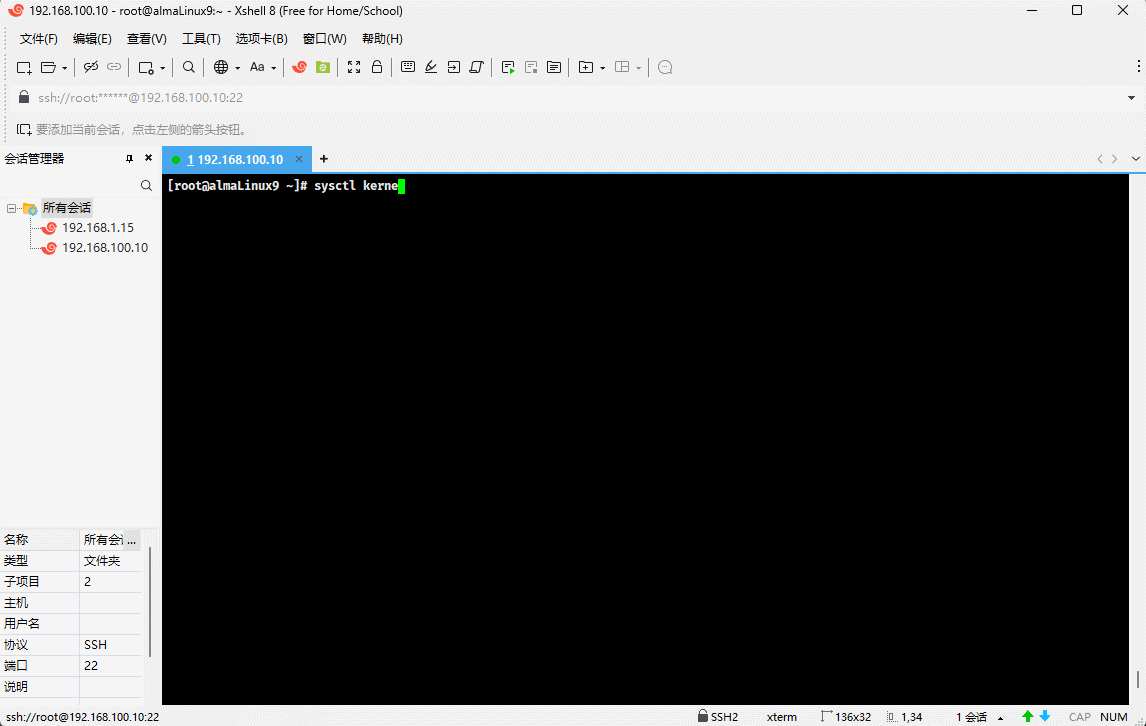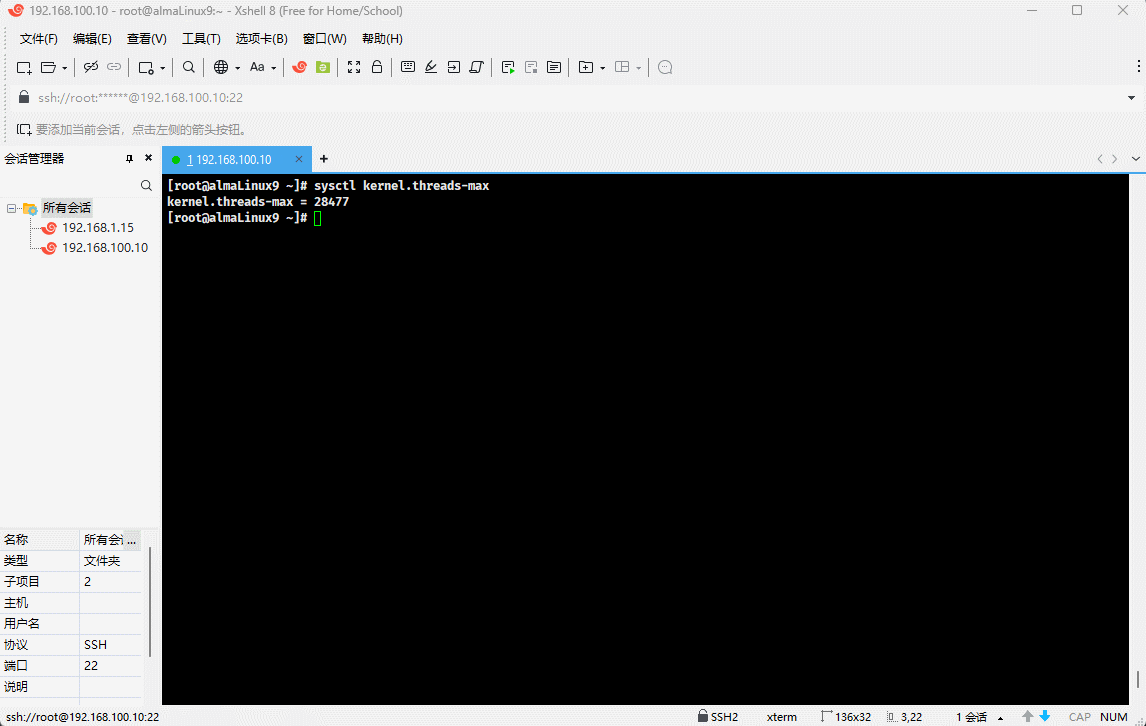
- 示例:查询所有的内核参数
sysctl -a
- 示例:修改指定的内核参数(临时生效)
sysctl -w kernel.threads-max=10240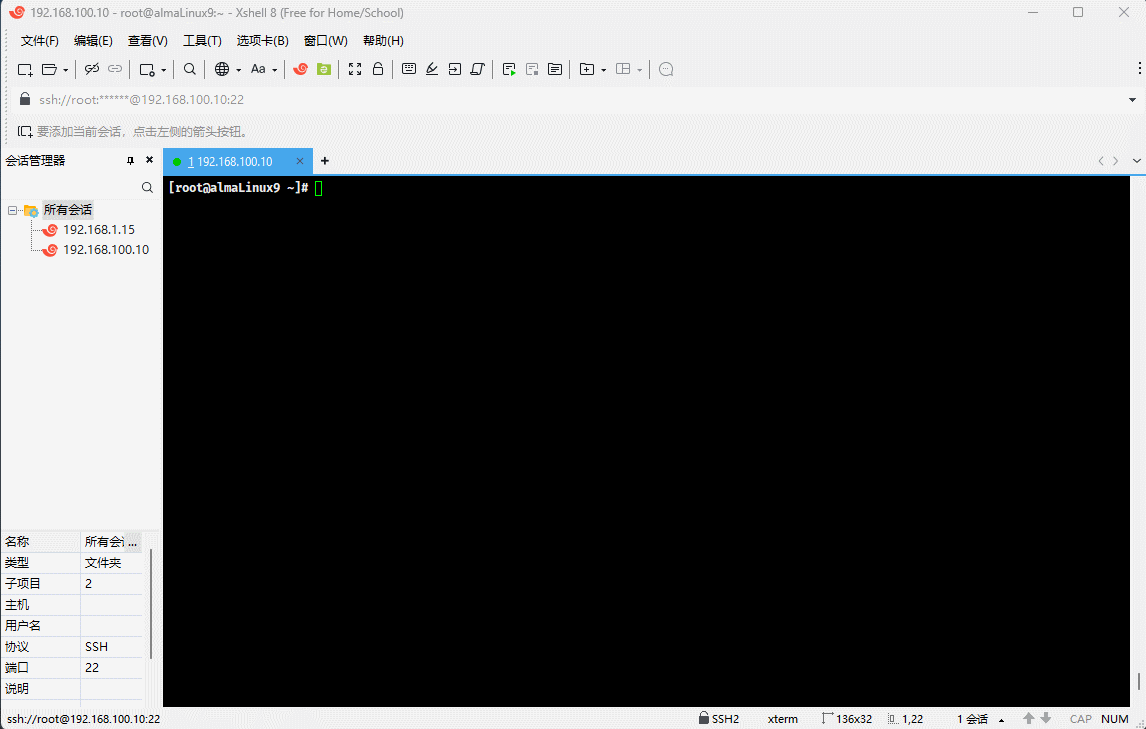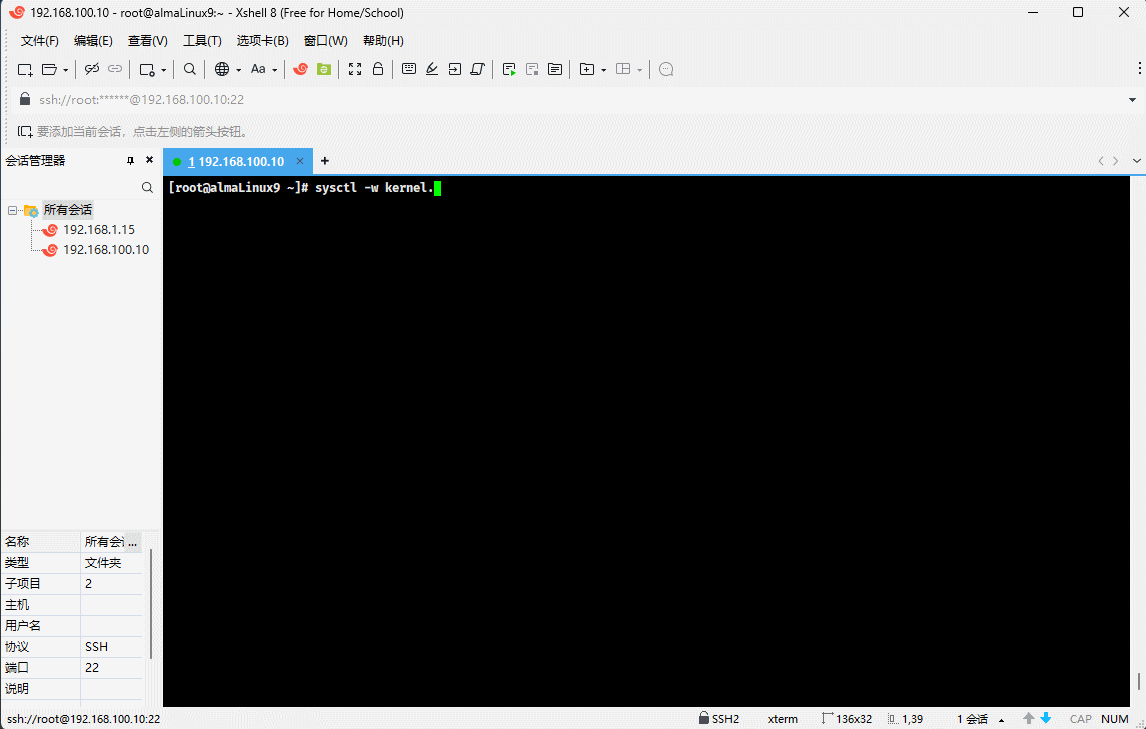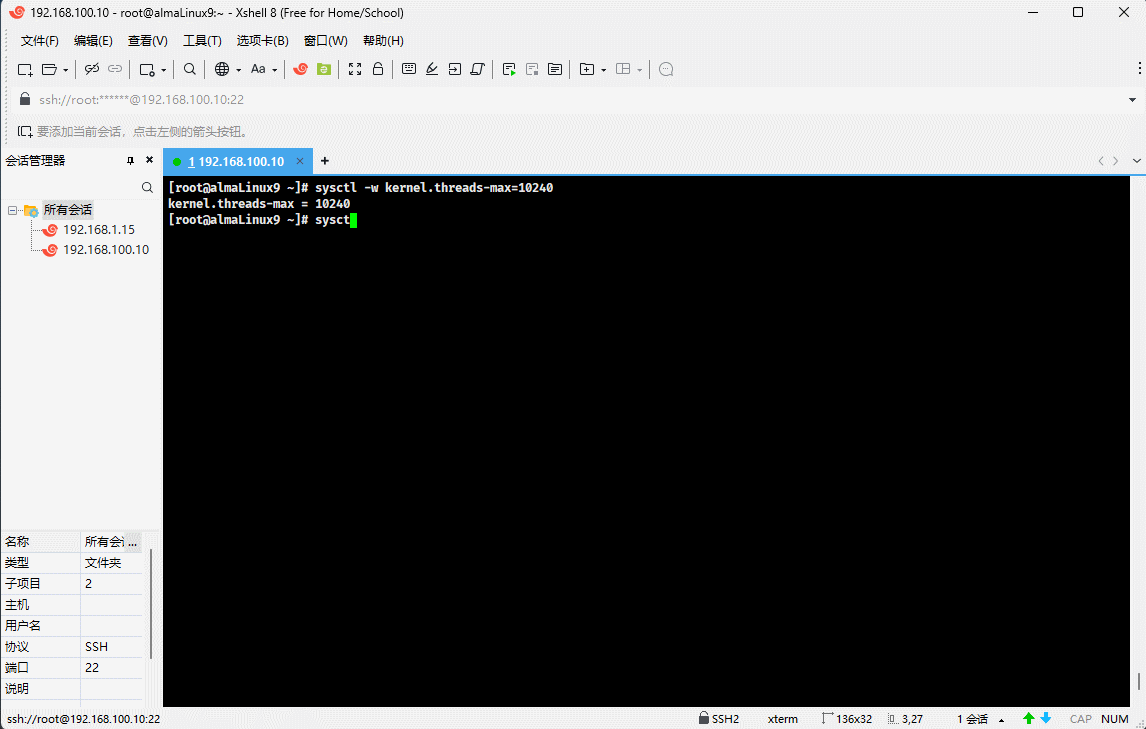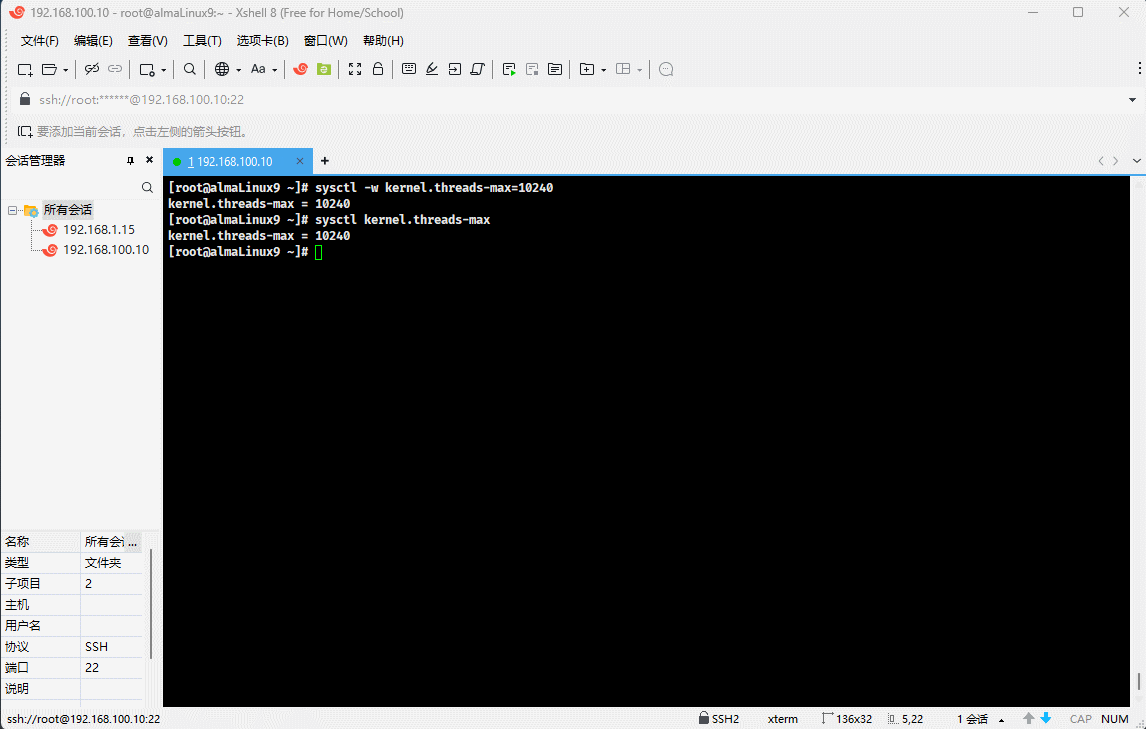
2.4.2.2.3 通过命令查询(用户级别)
- ulimit 可以在运行时控制用户级别:
ulimit [-a][-u]提醒
- ① ulimit 用于控制进程资源使用的重要命令:
- -a:查看当前用户的所有资源限制。
- -u:查看当前用户的最大线程数。
- -u 8192:修改当前用户的最大线程数为 8192。
- ② ulimit 的配置文件是 /etc/security/limits.conf,可以修改此文件,实现永久修改。
- 示例:查看当前用户的所有资源限制
ulimit -a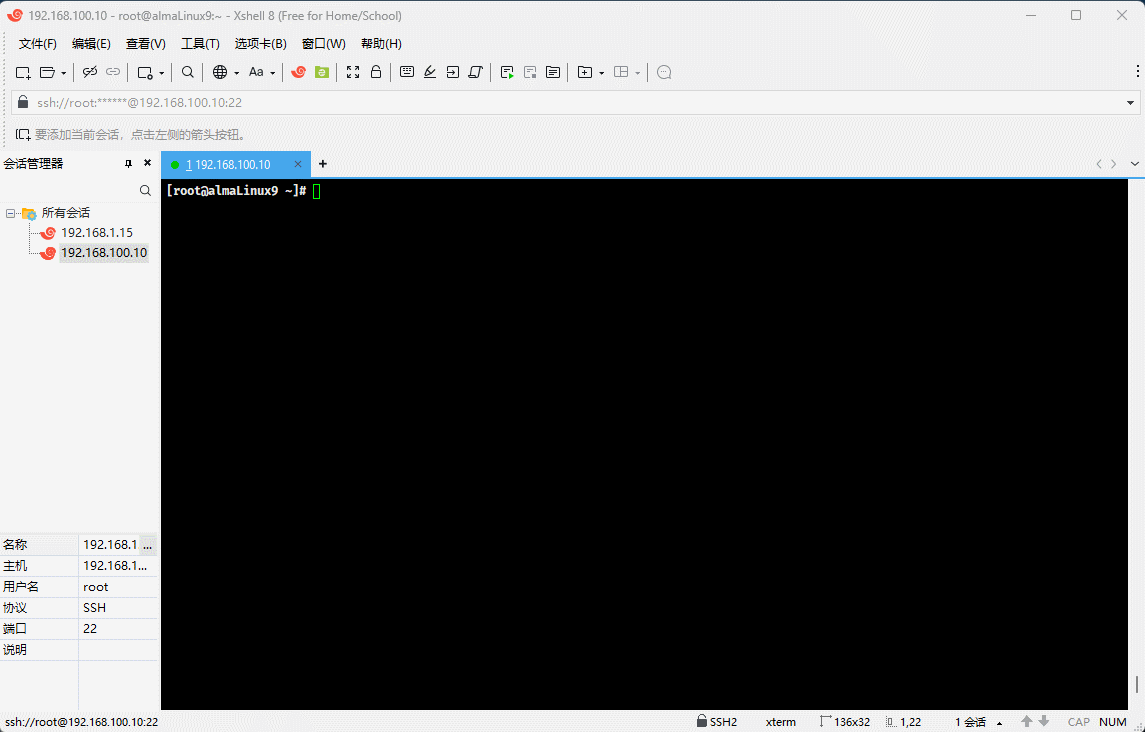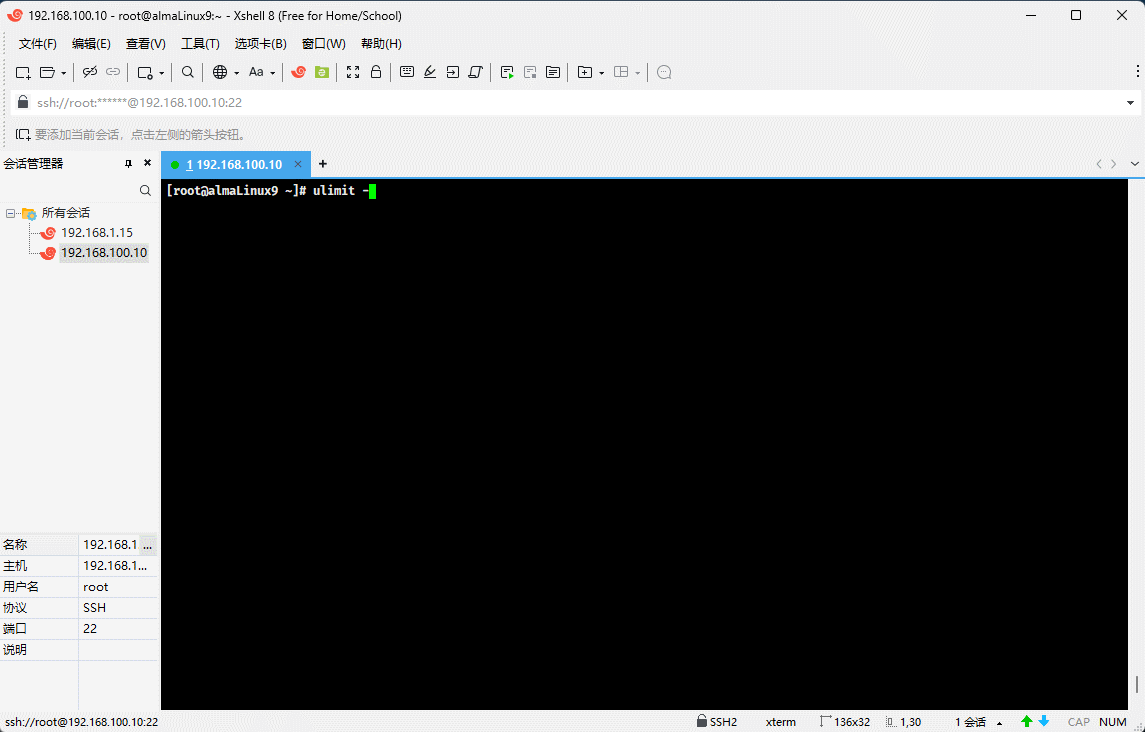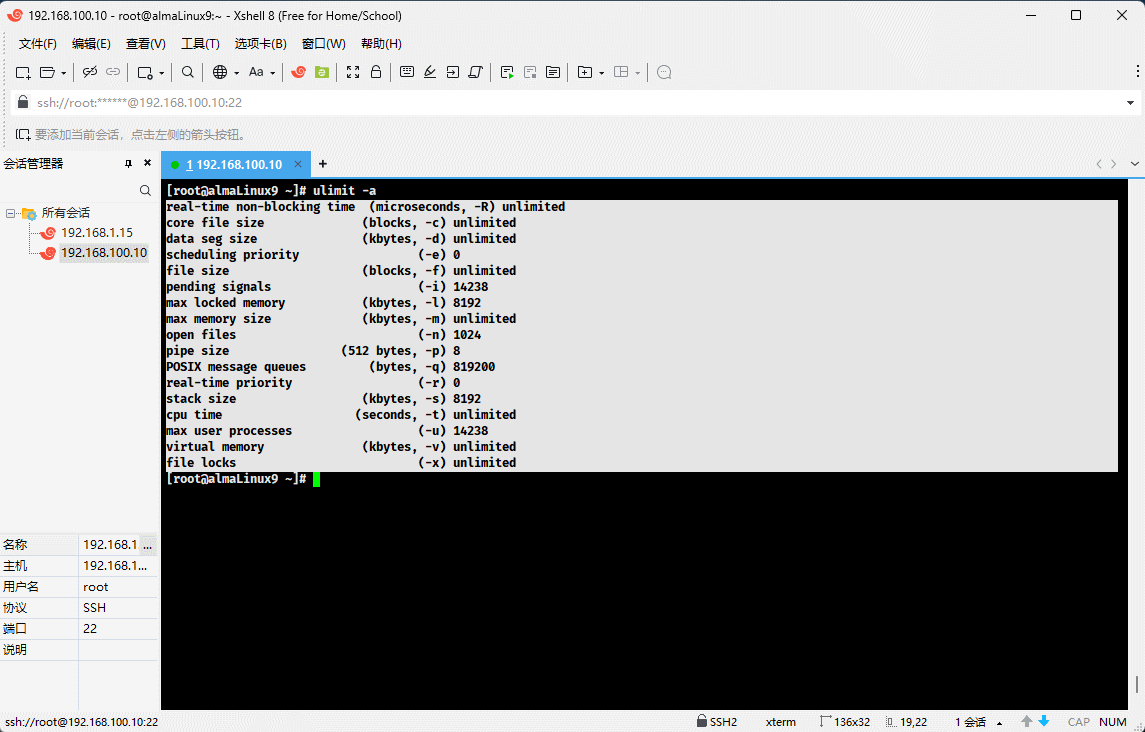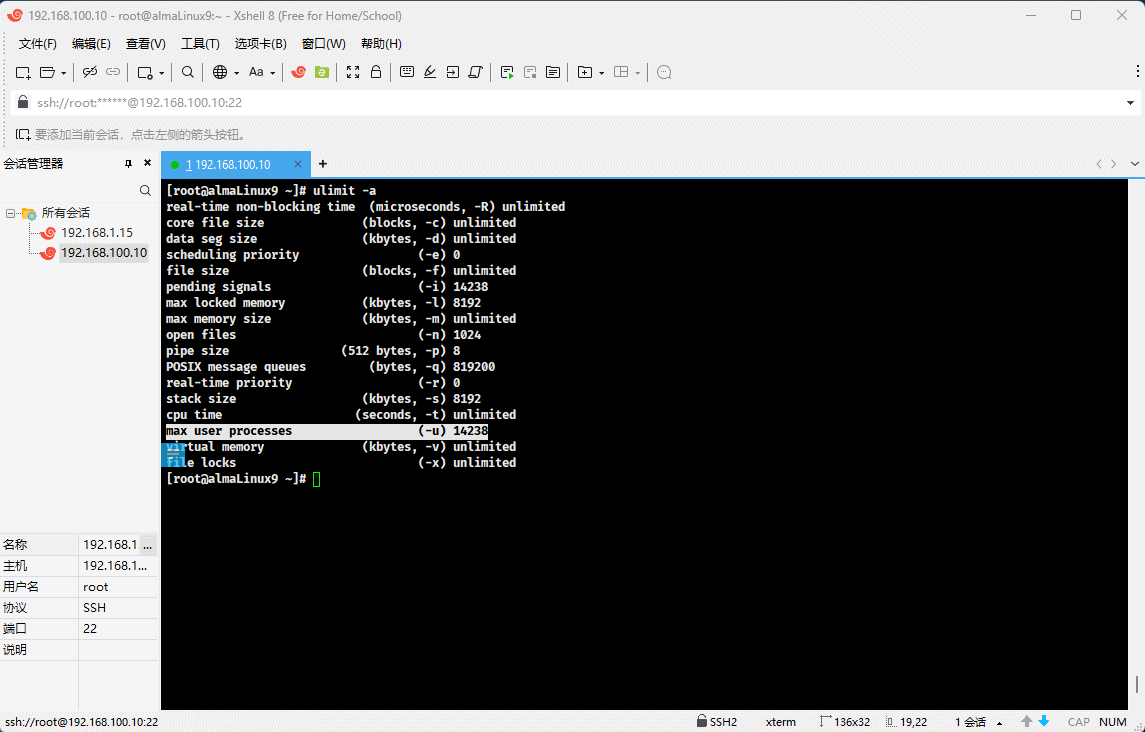
- 示例:查看当前用户的最大线程数
ulimit -u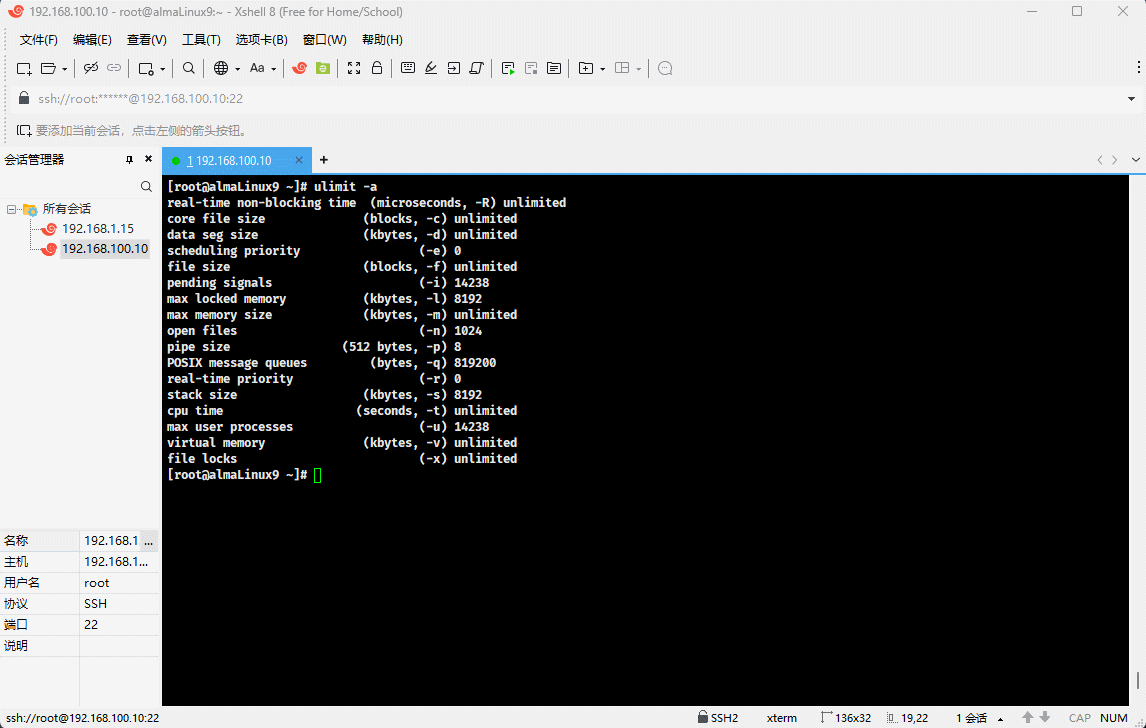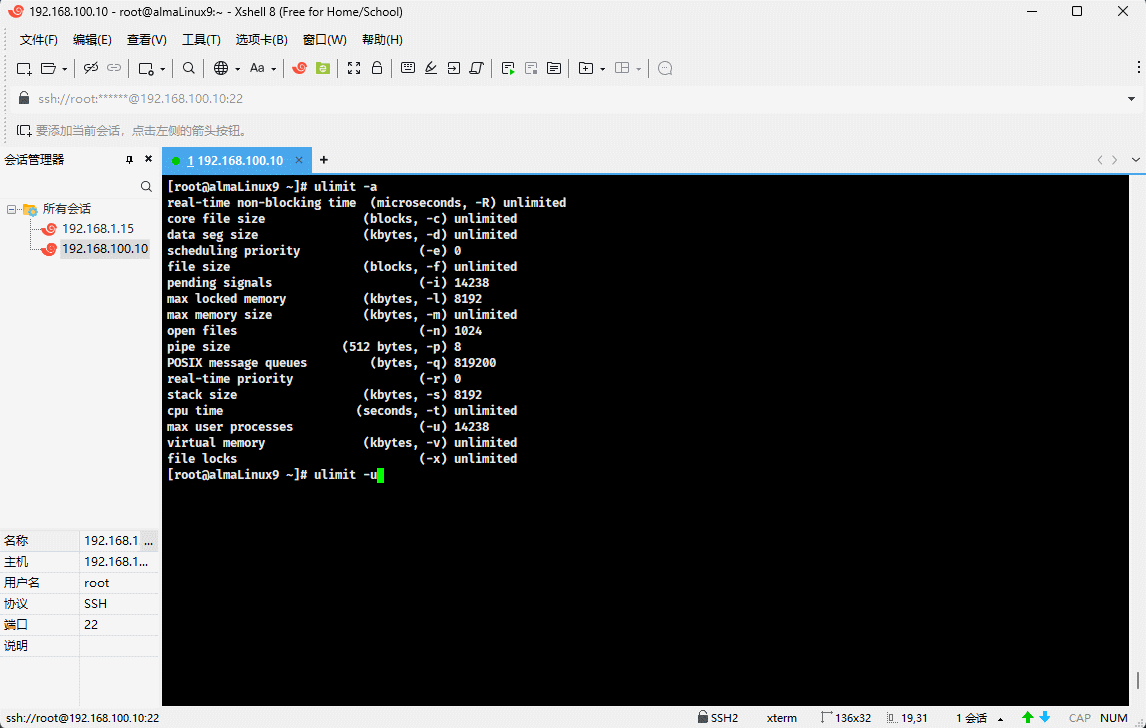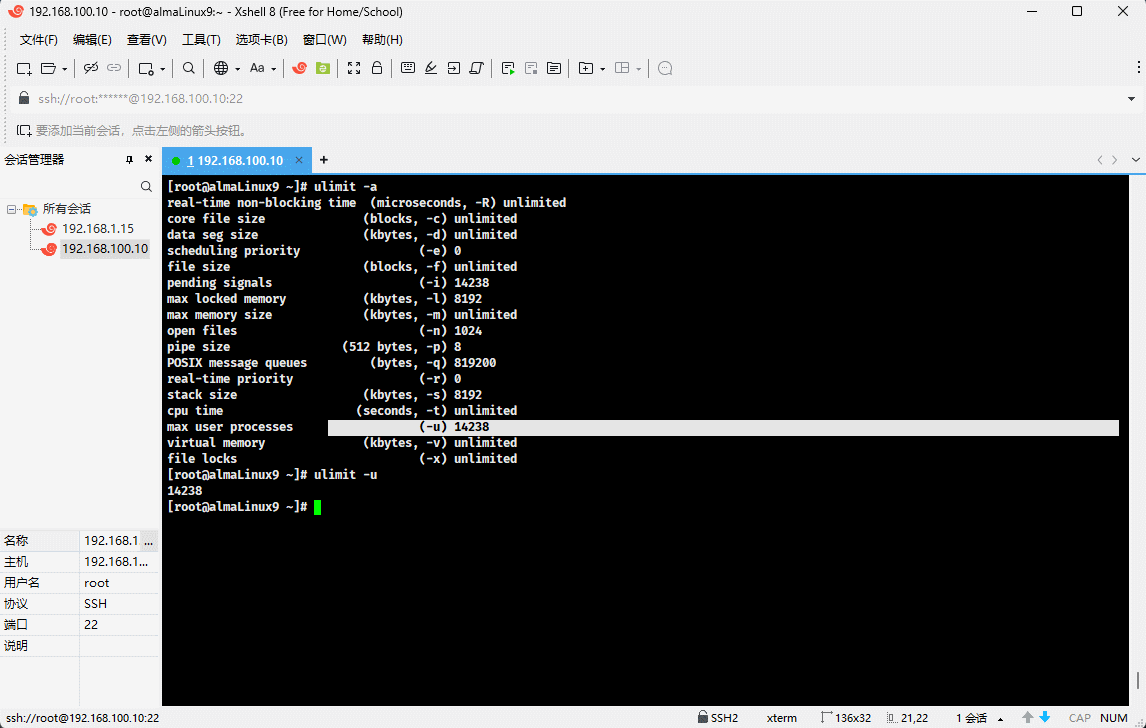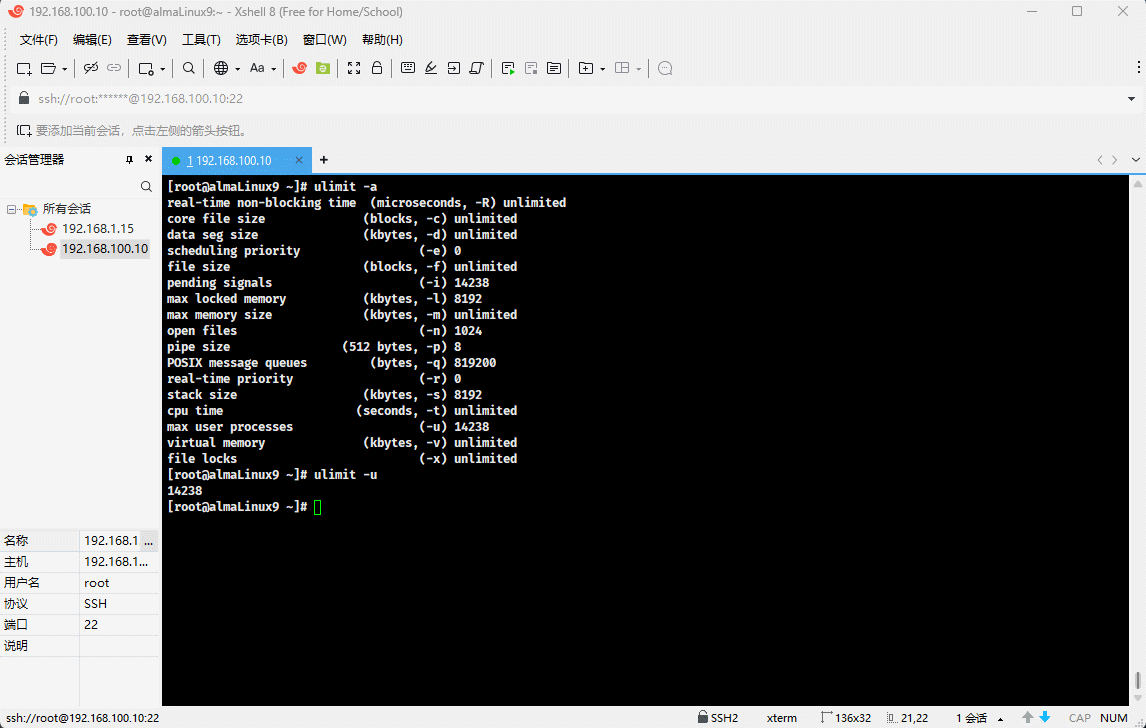
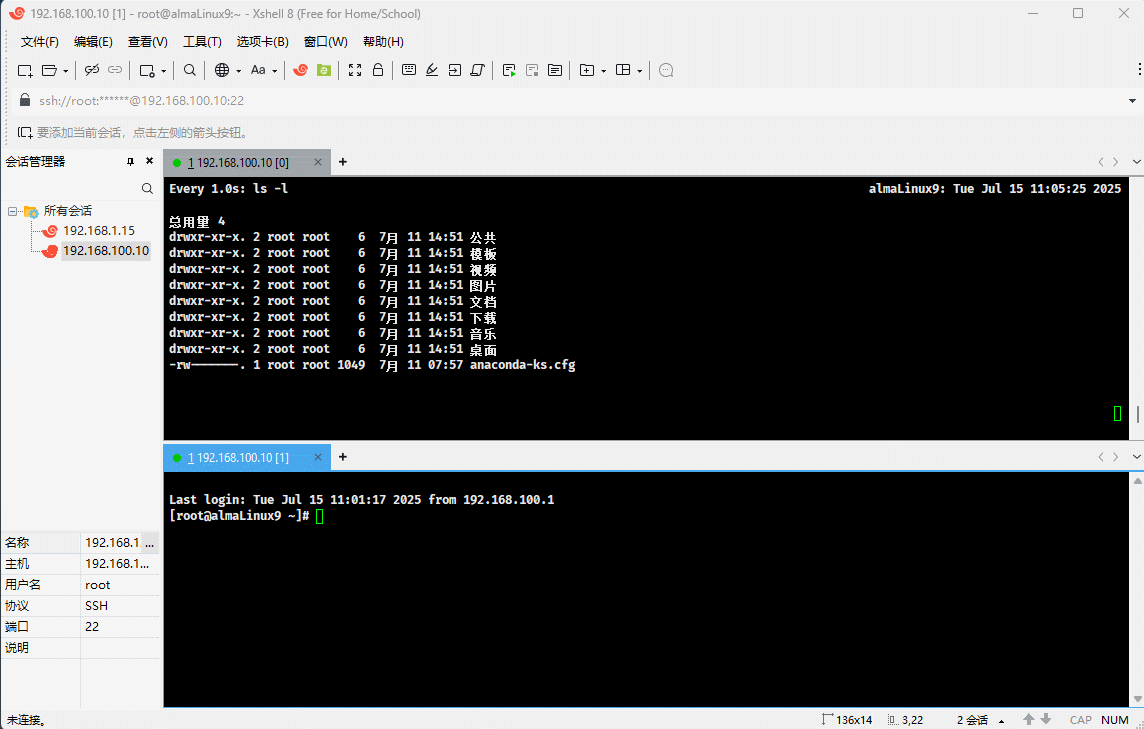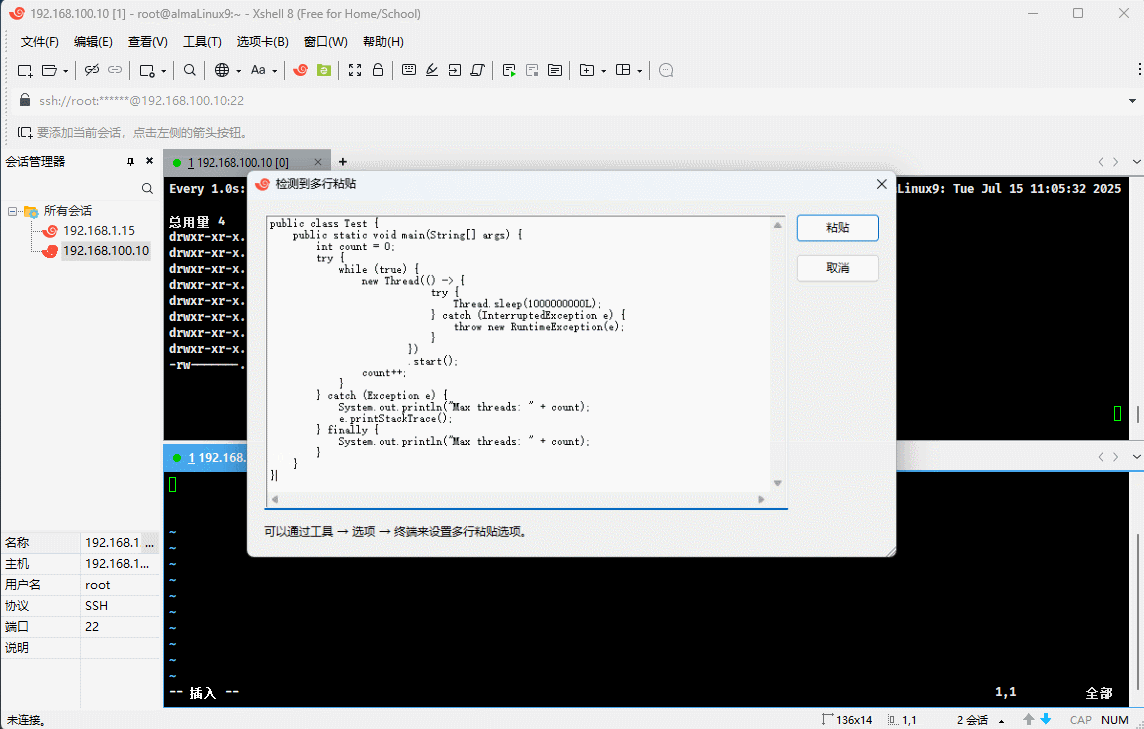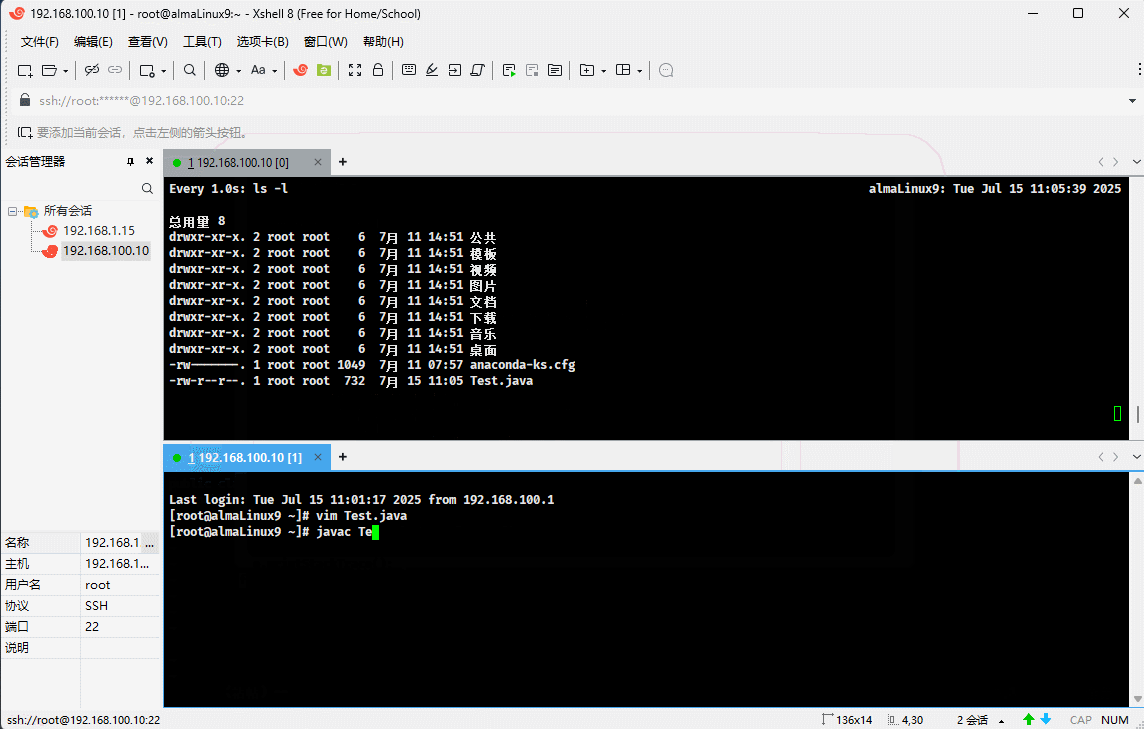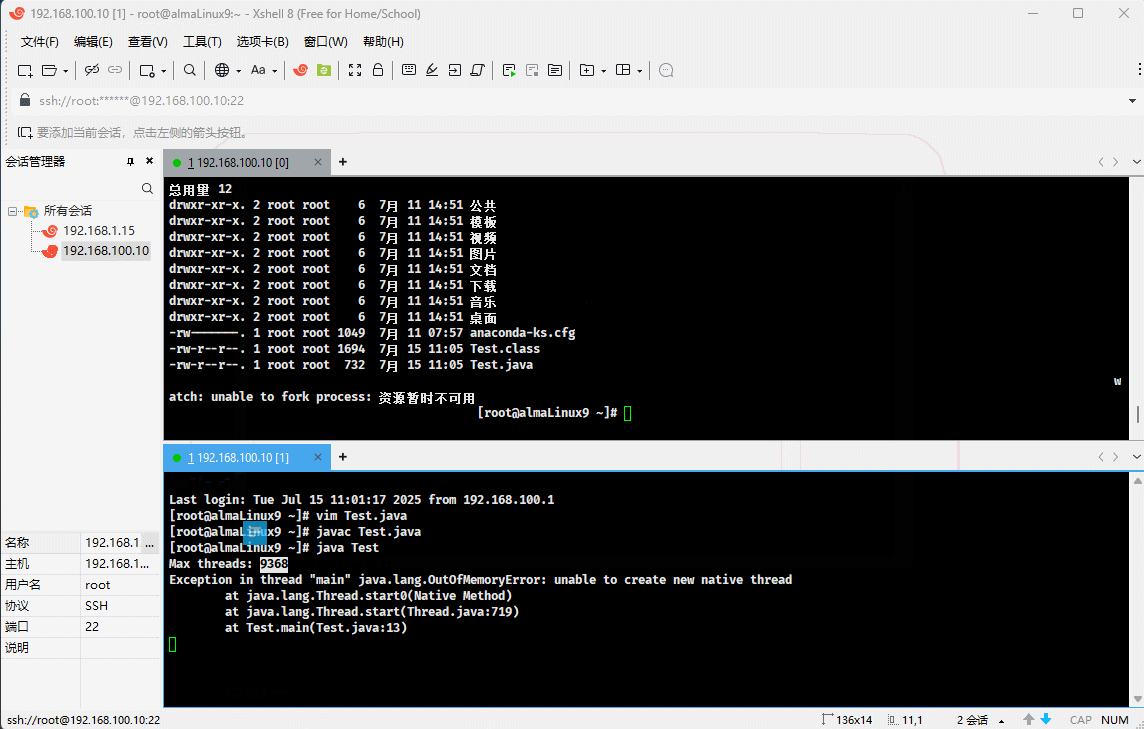
- 示例:使用 Java 测试当前用户的最大线程数
public class Test {
public static void main(String[] args) {
int count = 0;
try {
while (true) {
new Thread(() -> {
try {
Thread.sleep(1000000000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
})
.start();
count++;
}
} catch (Exception e) {
System.out.println("Max threads: " + count);
e.printStackTrace();
} finally {
System.out.println("Max threads: " + count);
}
}
}
2.4.3 用户线程
- 用户线程指的是完全建立在用户自己的程序线程库上,系统内核不能感知到用户线程的存在及如何实现的。
- 用户线程的创建、同步、销毁和调度完全在用户态中完成,不需要在频繁切换内核态,因此速度很快。
提醒
由于是一个进程对应多个用户线程,这种方式是 1:N 的线程模型。

- 优点:在用户自己的程序中实现,不需要调用内核,操作非常快速且低消耗,也能够支持规模更大的线程数量。
- 缺点:
- 所有的线程操作都需要由用户处理,如:线程的创建、销毁、切换、调度都是用户需要考虑的问题。
- 操作系统只将处理器的资源分配到进程程度,如:阻塞如何处理、多处理器如今分配资源等问题都需要由用户解决。
2.4.4 用户线程 + 内核线程
- 用户线程 + 内核线程混合实现的方式:既存在用户线程,又存在轻量级进程(内核线程)。
提醒
- ① 用户线程建立在用户态中;所以,不需要频繁切换内核态,保证了速度的高效。
- ② 轻量级进程(内核线程)为用户线程和内核线程的桥梁,即:可以使用内核提供的线程调度功能处理用户线程中存在的问题。
- ③ 用户线程和轻量级进程的比例是不确定的,这种方式是 N:M 的线程模型。

2.5 再次认识 Java 中的线程
- 线程是 Java 程序执行的一条路径,每一个线程都有自己的虚拟机栈、程序计数器(指向正在行的指令指针)。当启动了一个 Java 虚拟机(JVM)的时候,操作系统就会创建一个新的 Java 进程(JVM 进程),然后由 JVM 进程创建很多线程。
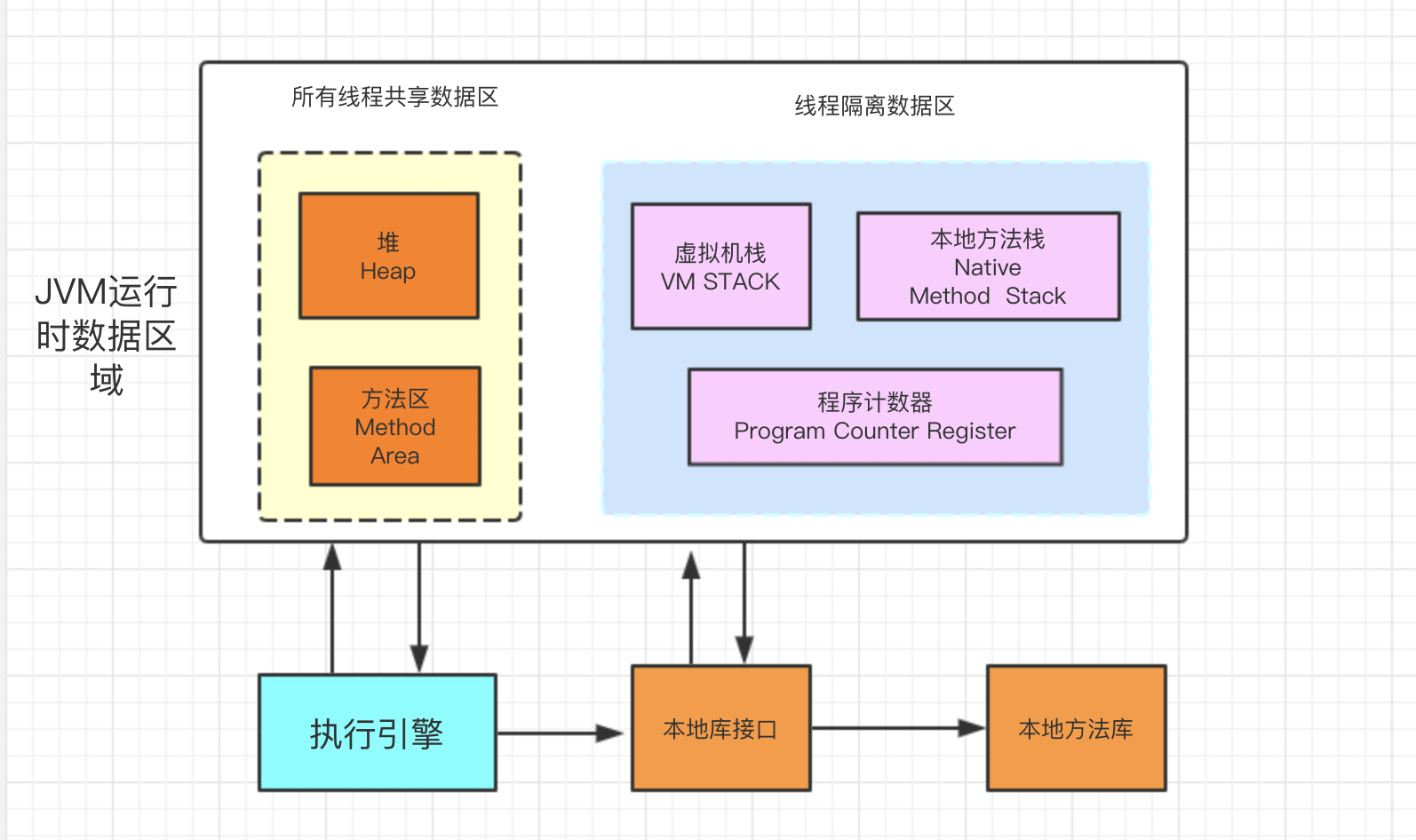
- Java 中的线程在 JDK1.2 之前,是采用
用户线程方式实现的,其被称为绿色线程;但是,由于太过繁琐以及复杂,最终放弃。 - Java 中的线程在 JDK1.3 之后,是采用
内核线程方式实现的,即:每个线程都是直接映射到操作系统的内核线程,JVM 自己不会去干涉线程的调度,可以设置线程优先级给操作系统提供调度建议;但是,线程的调度全权交给底层的操作系统去处理,至于何时冻结或唤醒线程、给线程分配多少处理器执行时间、把线程分配给哪个处理器核心去执行等,都是由操作系统来调度完成的。
2.6 Java 中创建线程的方式
2.6.1 概述
- Java 创建线程很多方式,如下所示:
- ①
继承 Thread 类的方式创建线程。 - ②
实现 Runnable 接口的方式创建线程。 - ③
利用 Callable 接口和 Future 接口的方式创建线程。 - ④
通过线程池的方式创建线程。 - ⑤
SpringBoot 提供的 ThreadPoolTaskExecutor。
- ①
提醒
在 JDK21 之后,Java 正式推出了虚拟线程!!!
2.6.2 继承 Thread 类的方式
- 创建线程的步骤:
- ①
自己定义一个类继承 Thread 类。 - ②
重写 run 方法。 - ③
创建子类的对象,调用 start() 方法启动线程。
- ①
提醒
- ① 优点:编程比较简单,可以直接使用 Thread 类中的方法。
- ② 缺点:可扩展性较差,不能再继承其他的类。
- 示例:
package com.github.thread.demo1;
public class MyThread extends Thread {
@Override
public void run() {
// 书写线程要执行的代码,即:业务逻辑
final String name = Thread.currentThread().getName();
for (int i = 0; i < 100; i++) {
System.out.println(name + i);
}
}
}package com.github.thread.demo1;
public class Test {
public static void main(String[] args) {
/*
* Java 中实现线程的第一种方式:
* 1. 创建一个继承 Thread 类的子类。
* 2. 重写 run 方法,在 run 方法中编写线程的逻辑
* 3. 然后创建该子类的实例,调用 start 方法启动线程
*
* 注意:start 方法会调用 run 方法,但是 start 方法是异步执行的,run 方法是同步执行的
* 注意:run 方法中不能抛出异常,否则会导致线程终止
* 注意:run 方法中不能调用 yield 方法,否则会导致线程调度器无法调度该线程
* */
MyThread t = new MyThread();
t.start();
for (int i = 0; i < 100; i++) {
System.out.println("主线程:" + i);
}
}
}2.6.3 实现 Runnable 接口的方式
- 创建线程的步骤:
- ①
自定义定义一个类实现 Runnable 接口。 - ②
重写 run 方法。 - ③
创建自己类的对象。 - ④
创建一个 Thread 类的对象,将自己类的对象作为构造方法参数,调用 start() 方法启动线程。
- ①
提醒
- ① 优点:扩展性强,实现该接口的同时还可以继承其他类。
- ② 缺点:编程相对复杂,不能直接使用 Thread 类中的方法。
- 示例:
package com.github.thread.demo1;
public class MyRunnable implements Runnable {
@Override
public void run() {
// 书写线程要执行的代码,即:业务逻辑
String name = Thread.currentThread().getName();
for (int i = 0; i < 100; i++) {
System.out.println(name + i);
}
}
}package com.github.thread.demo1;
public class Test {
public static void main(String[] args) {
// 创建 Runnable 实现类对象
Runnable r = new MyRunnable();
// 创建 Thread 对象,将 Runnable 实现类对象作为参数传递给 Thread 类的构造方法
Thread t = new Thread(r);
// 调用 Thread 类的 start() 方法启动线程
t.start();
for (int i = 0; i < 100; i++) {
System.out.println("主线程:" + i);
}
}
}
2.6.4 利用 Callable 接口和 Future 接口的方式
- 使用步骤:
- ①
创建一个类 MyCallable 实现 Callable 接口。 - ②
重写 call() 方法,返回值就表示线程执行的结果。 - ③
创建 MyCallable 类的对象,表示线程要执行的任务。 - ④
创建 FutureTask 类的对象,用来保存线程运行的结果。 - ⑤
创建 Thread 类的对象,并将 FutureTask 类对象作为构造方法的参数,并启动线程。 - ⑥
调用 FutureTask 类对象的 get() 方法,获取线程运行的结果。
- ①
提醒
- ① 优点:扩展性强,实现该接口的同时还可以继承其他类。
- ② 缺点:编程相对复杂,不能直接使用 Thread 类中的方法。
- 示例:
package com.github.thread.demo1;
import java.util.concurrent.Callable;
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i < 100; i++) {
sum += i;
}
System.out.println(Thread.currentThread().getName() + ":" + sum);
return sum;
}
}package com.github.thread.demo1;
import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
public class Test {
public static void main(String[] args) {
// 创建 Callable 实现类对象
Callable<Integer> r = new MyCallable();
// 创建 FutureTask 对象,将 Callable 实现类对象作为参数传递给 FutureTask 类的构造方法
FutureTask<Integer> ft = new FutureTask<>(r);
// 创建 Thread 对象,将 FutureTask 对象作为参数传递给 Thread 类的构造方法
Thread t = new Thread(ft);
t.start();
try {
// 获取 Callable 实现类对象计算结果
Integer sum = ft.get();
System.out.println("结果:" + sum);
} catch (Exception e) {
e.printStackTrace();
}
}
}
2.6.5 利用线程池的方式
- 使用步骤:
- ①
通过 Executors 类的静态工厂方法创建线程池对象。 - ②
通过调用线程池对象的 submit()、execute()、invokeAny() 以及 invokeAll() 方法将任务(线程)分配给线程池对象。 - ③
关闭线程池对象。
- ①
提醒
此处只是简单演示,后续会详细讲解!!!
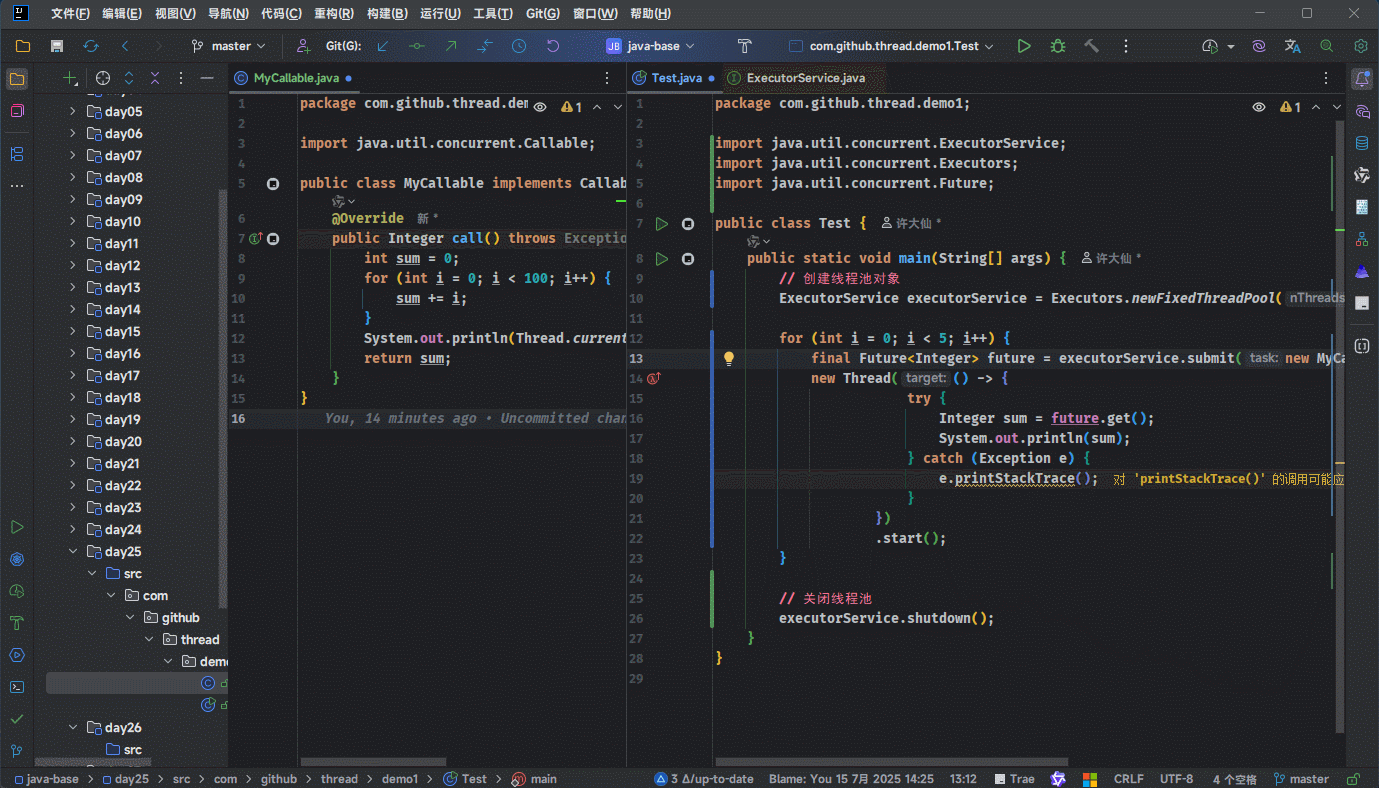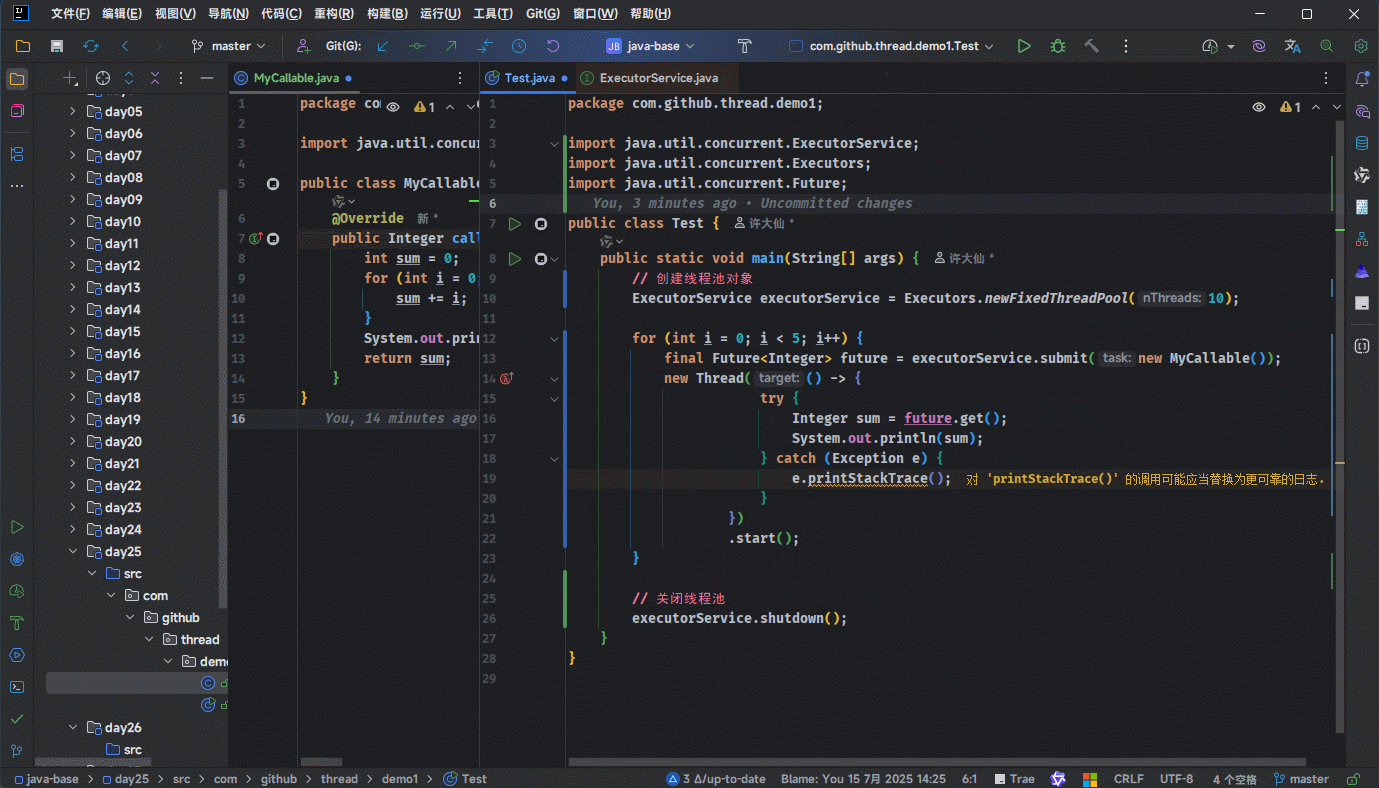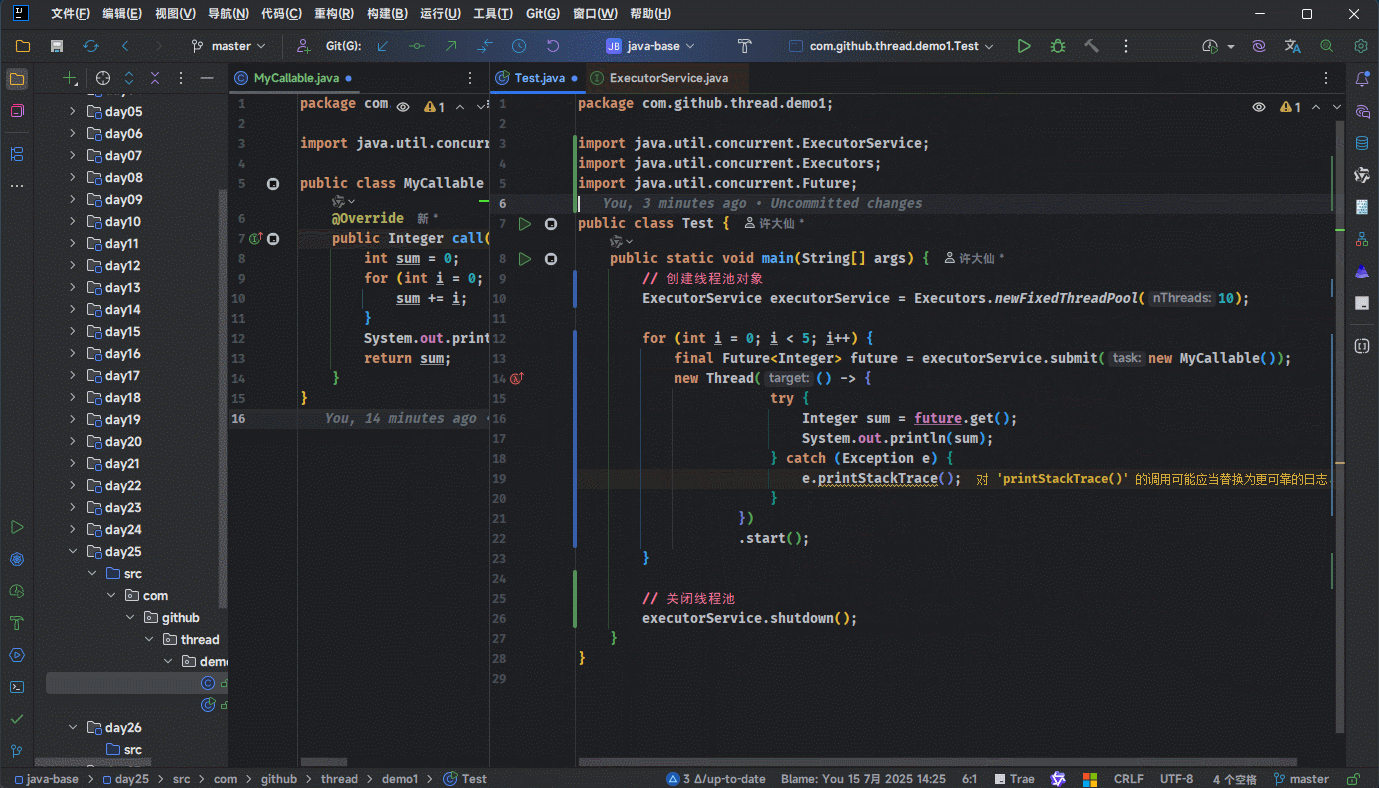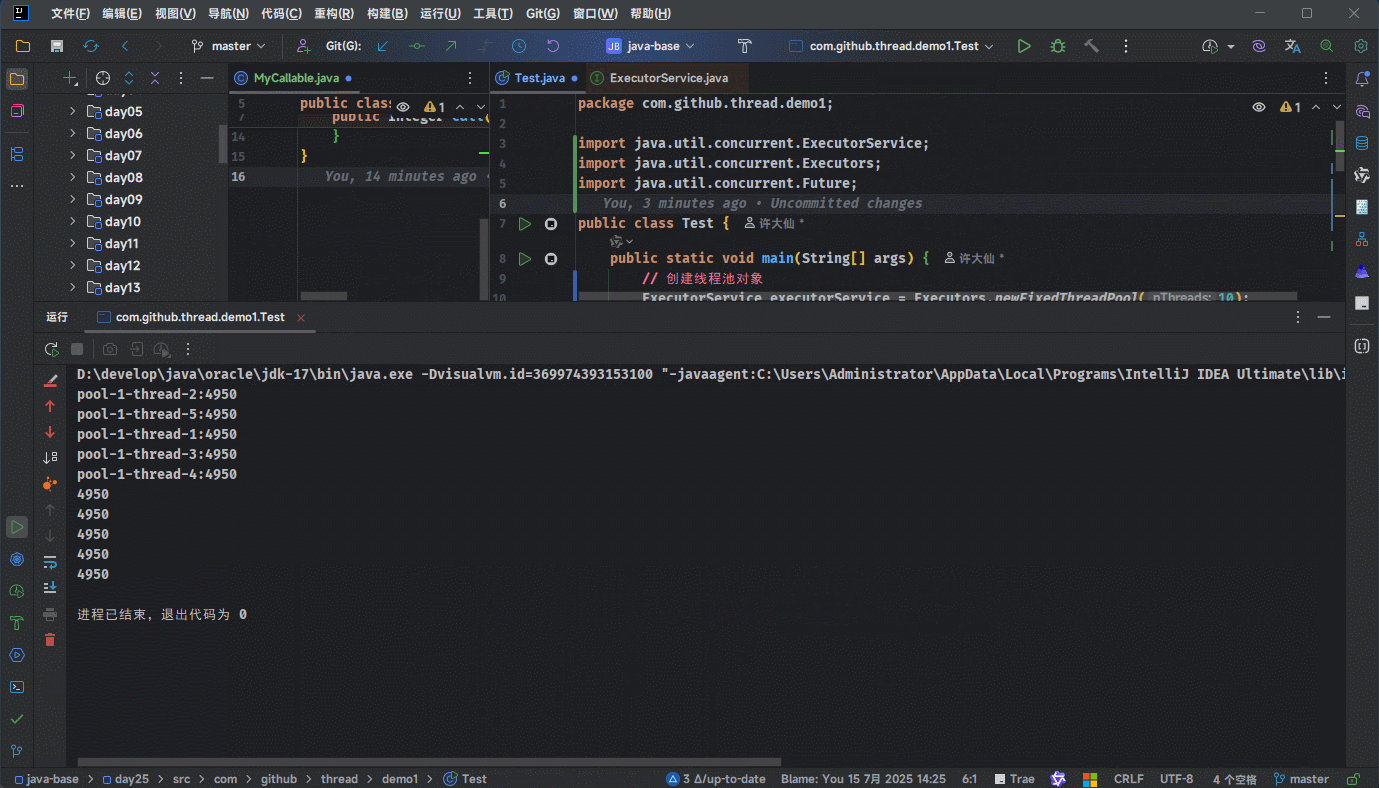
- 示例:
package com.github.thread.demo1;
import java.util.concurrent.Callable;
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i < 100; i++) {
sum += i;
}
System.out.println(Thread.currentThread().getName() + ":" + sum);
return sum;
}
}package com.github.thread.demo1;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class Test {
public static void main(String[] args) {
// 创建线程池对象
ExecutorService executorService = Executors.newFixedThreadPool(10);
for (int i = 0; i < 5; i++) {
final Future<Integer> future = executorService.submit(new MyCallable());
new Thread(() -> {
try {
Integer sum = future.get();
System.out.println(sum);
} catch (Exception e) {
e.printStackTrace();
}
})
.start();
}
// 关闭线程池
executorService.shutdown();
}
}
2.7 多线程调试技巧
- 需要进行多线程调试的代码是这样的,如下所示:
package com.github.thread.demo1;
public class Test {
public static void main(String[] args) {
String mainName = Thread.currentThread().getName();
System.out.println(mainName + ":开始运行");
Thread t1 = new Thread(() -> {
for (int i = 0; i < 3; i++) {
String name = Thread.currentThread().getName();
System.out.println(name + ":写代码");
}
});
t1.start();
Thread t2 = new Thread(() -> {
for (int i = 0; i < 3; i++) {
String name = Thread.currentThread().getName();
System.out.println(name + ":播放音乐");
}
});
t2.start();
System.out.println(mainName + ":结束运行");
}
}
- 因为要在 IDEA 中进行多线程调试,此处就需要在
run()或call()方法中设置断点:
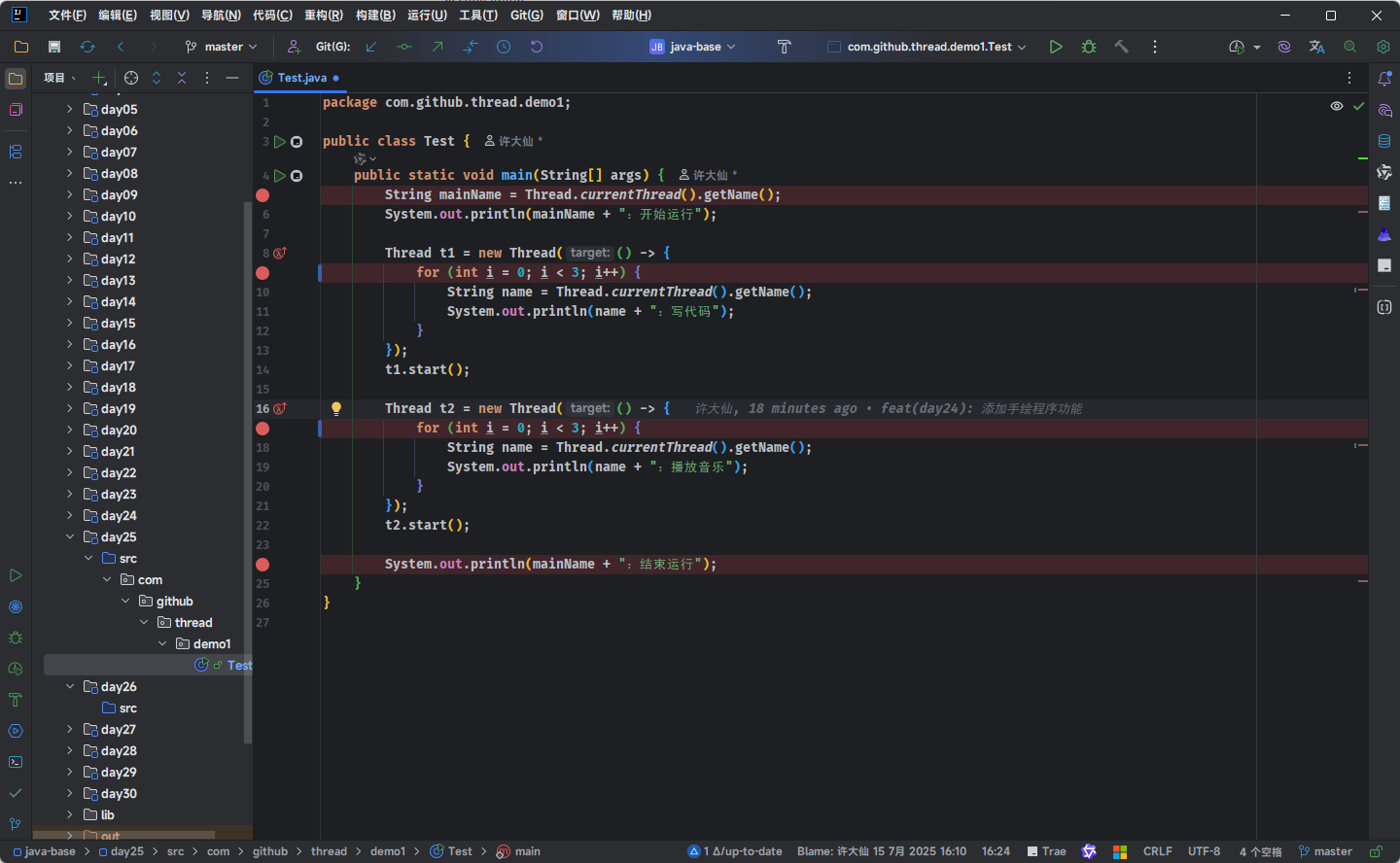
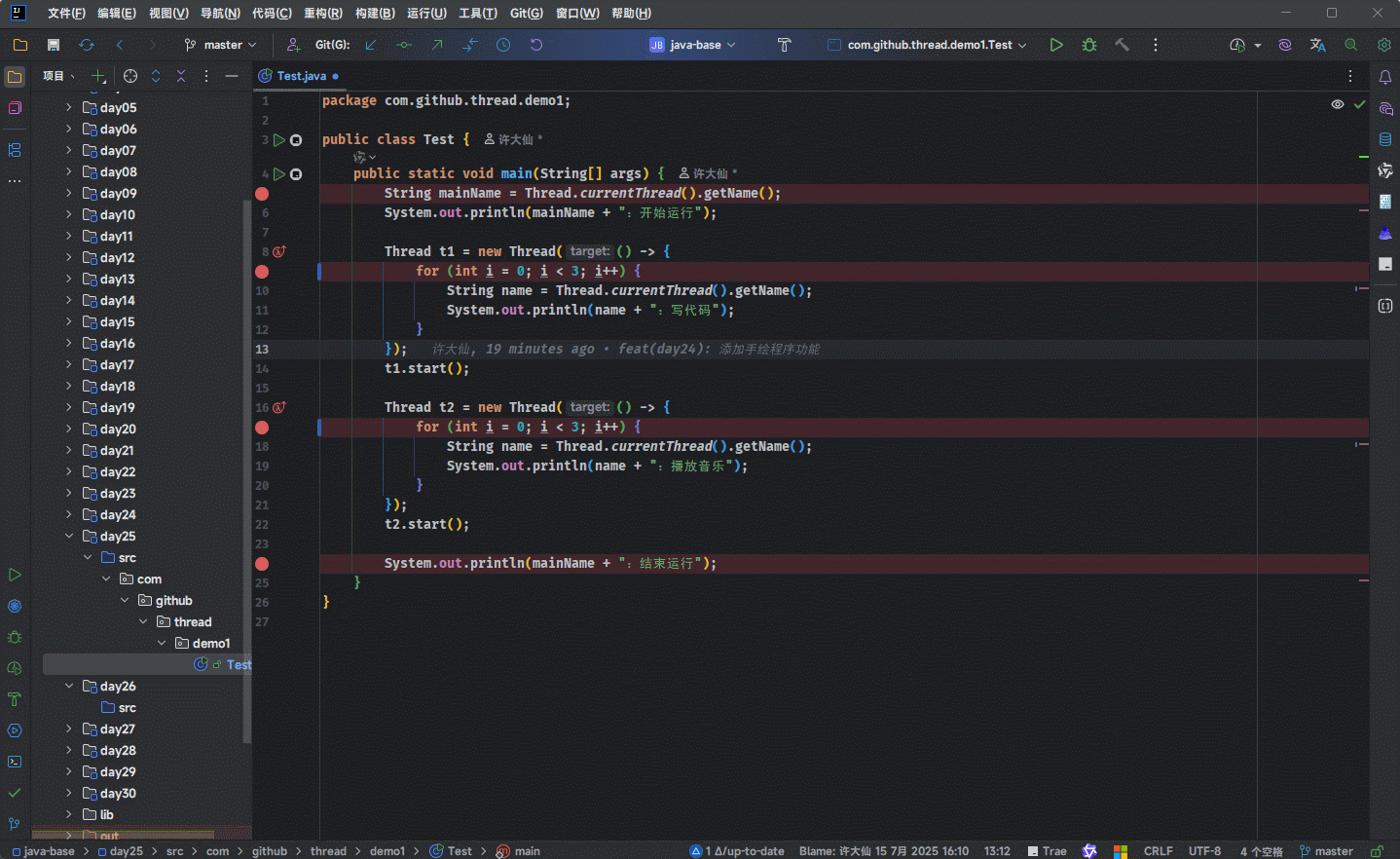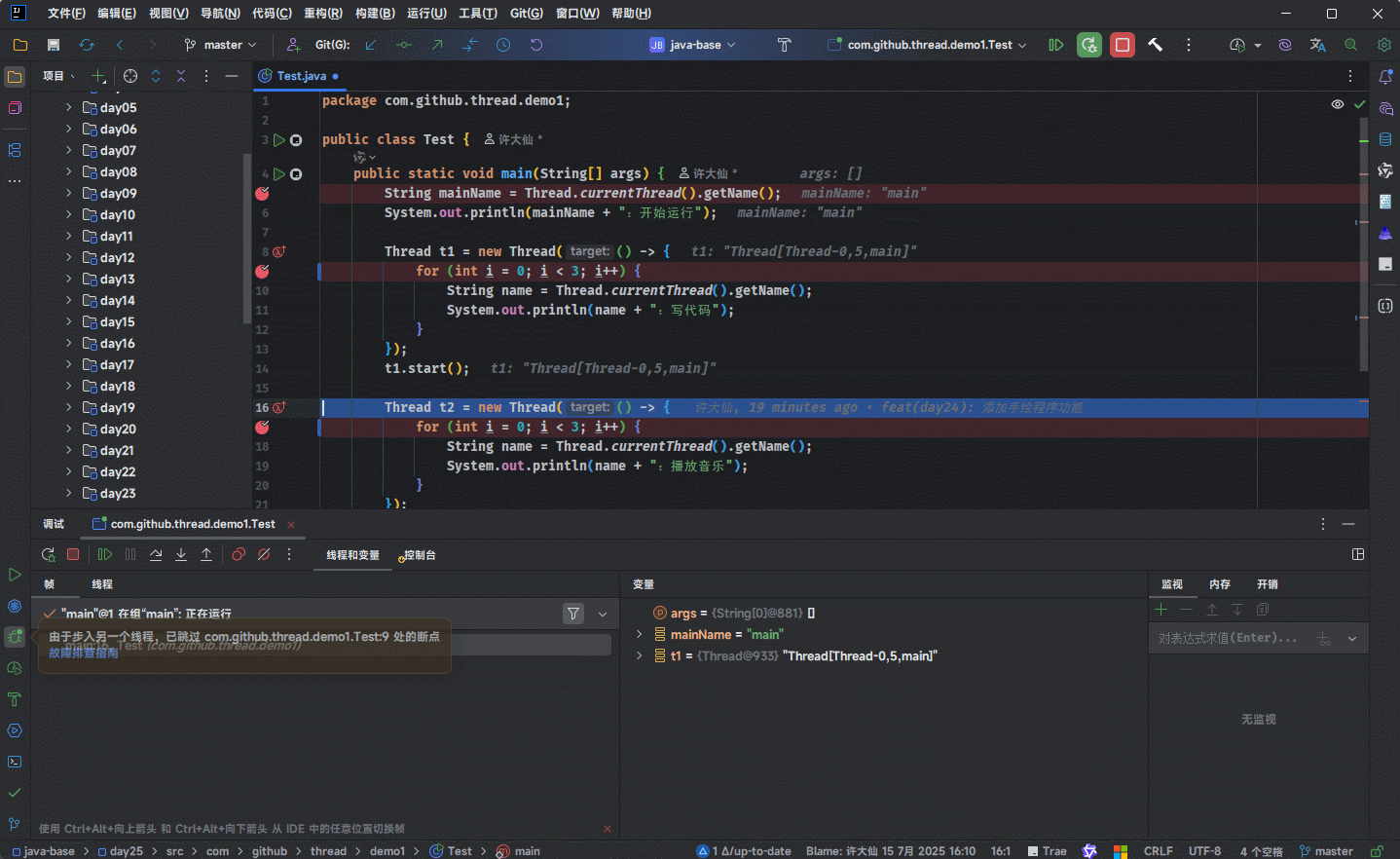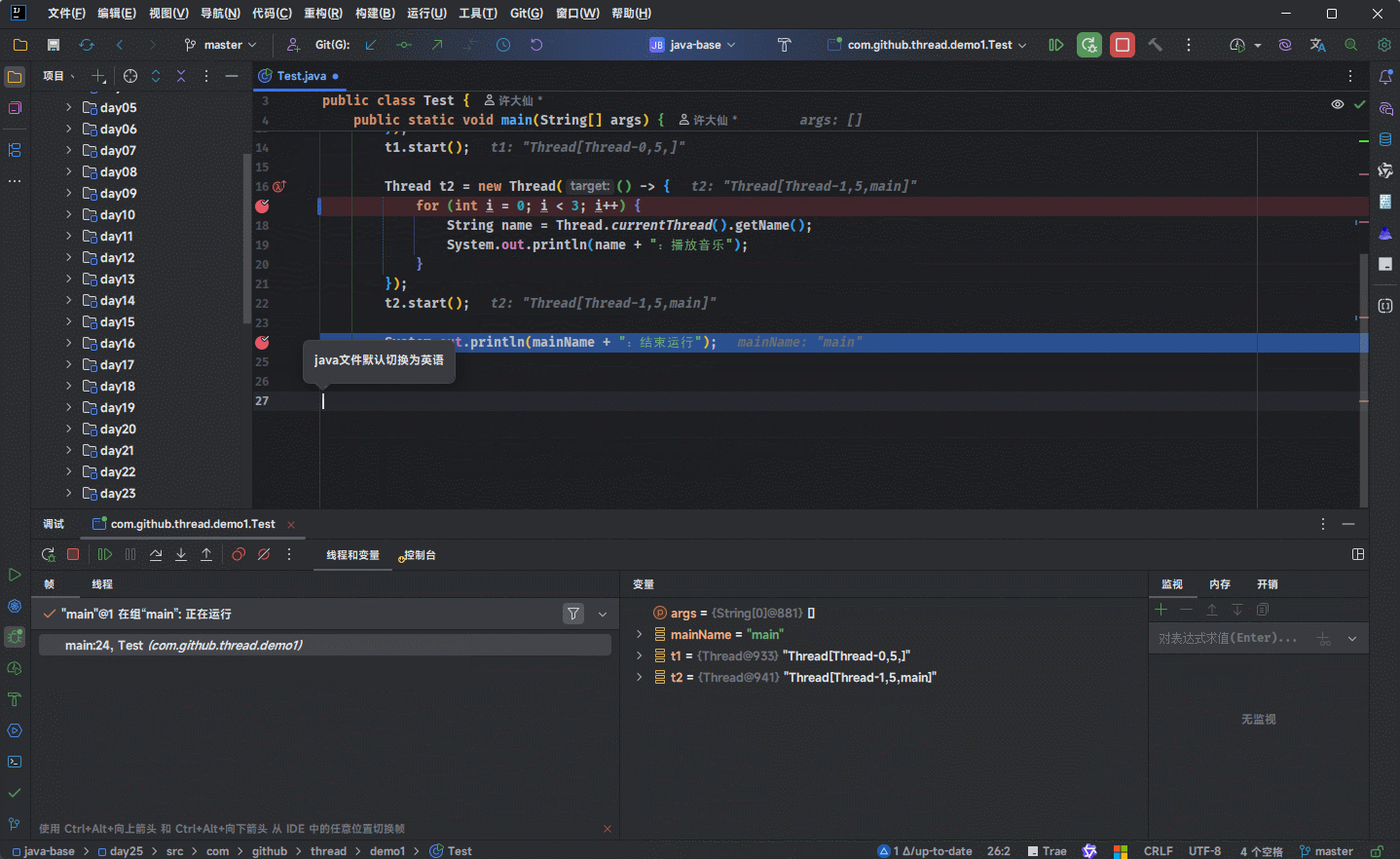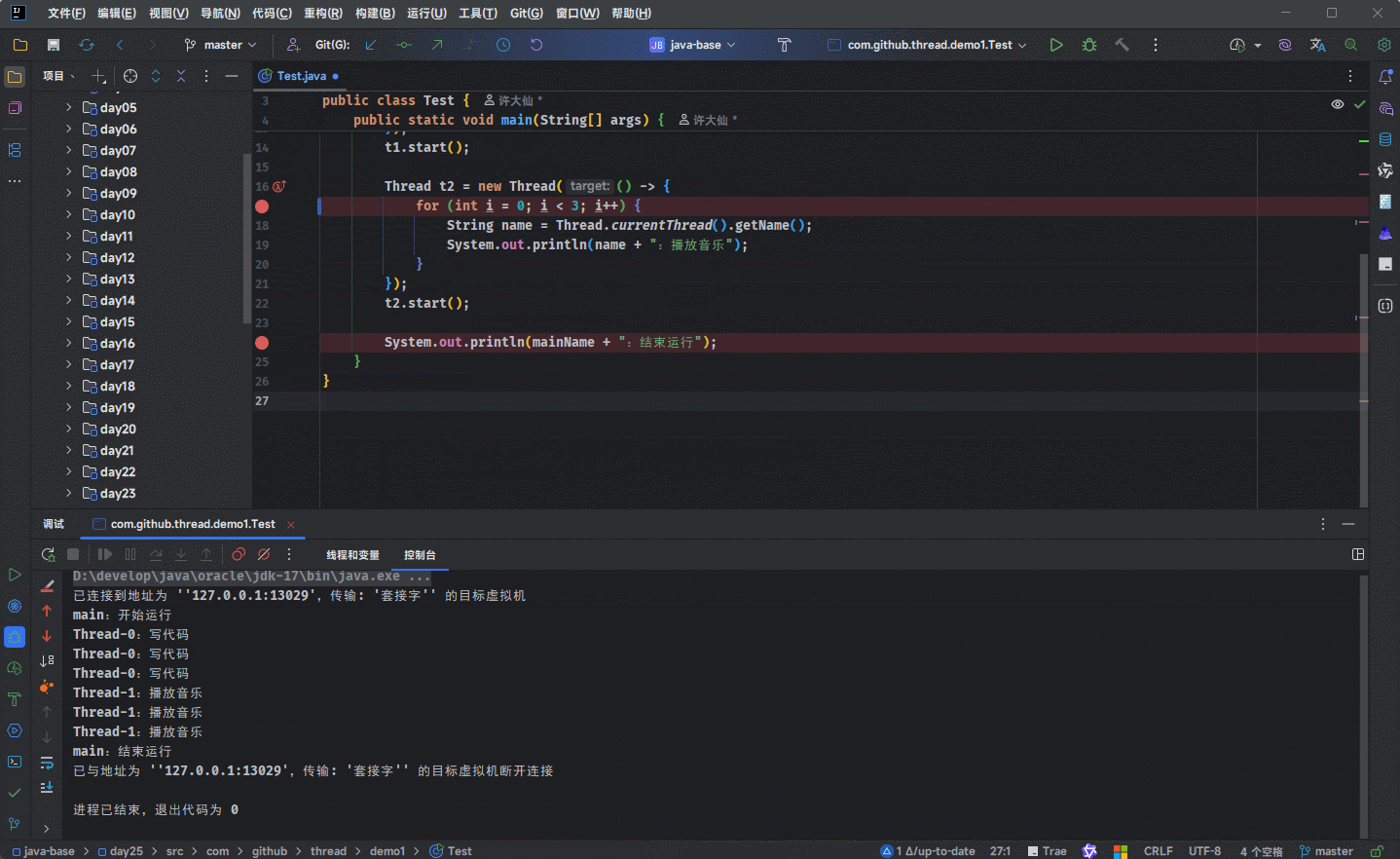
- 但是,当我们进行 debug 的时候,会发现就是进入不了
run()或call()方法:
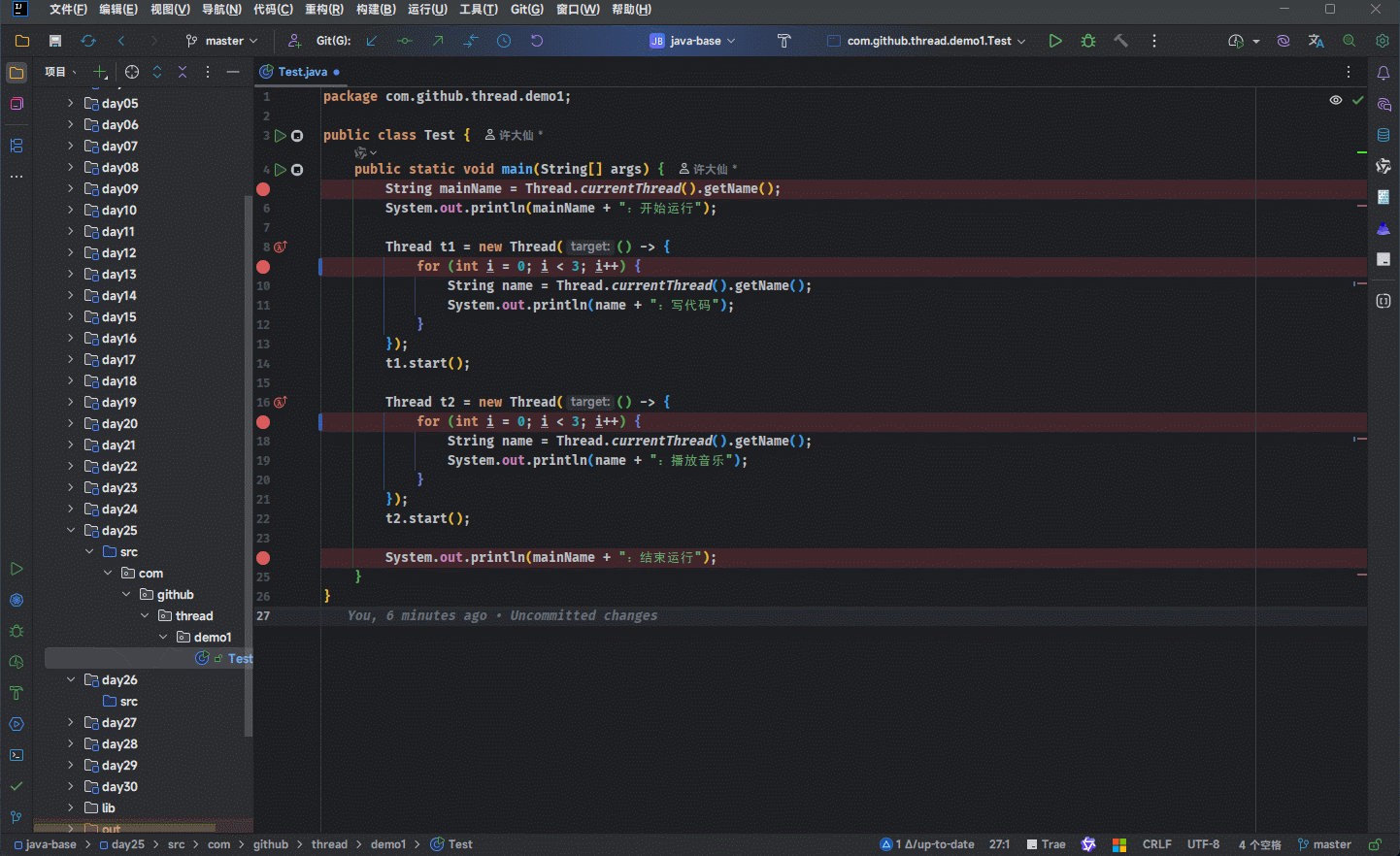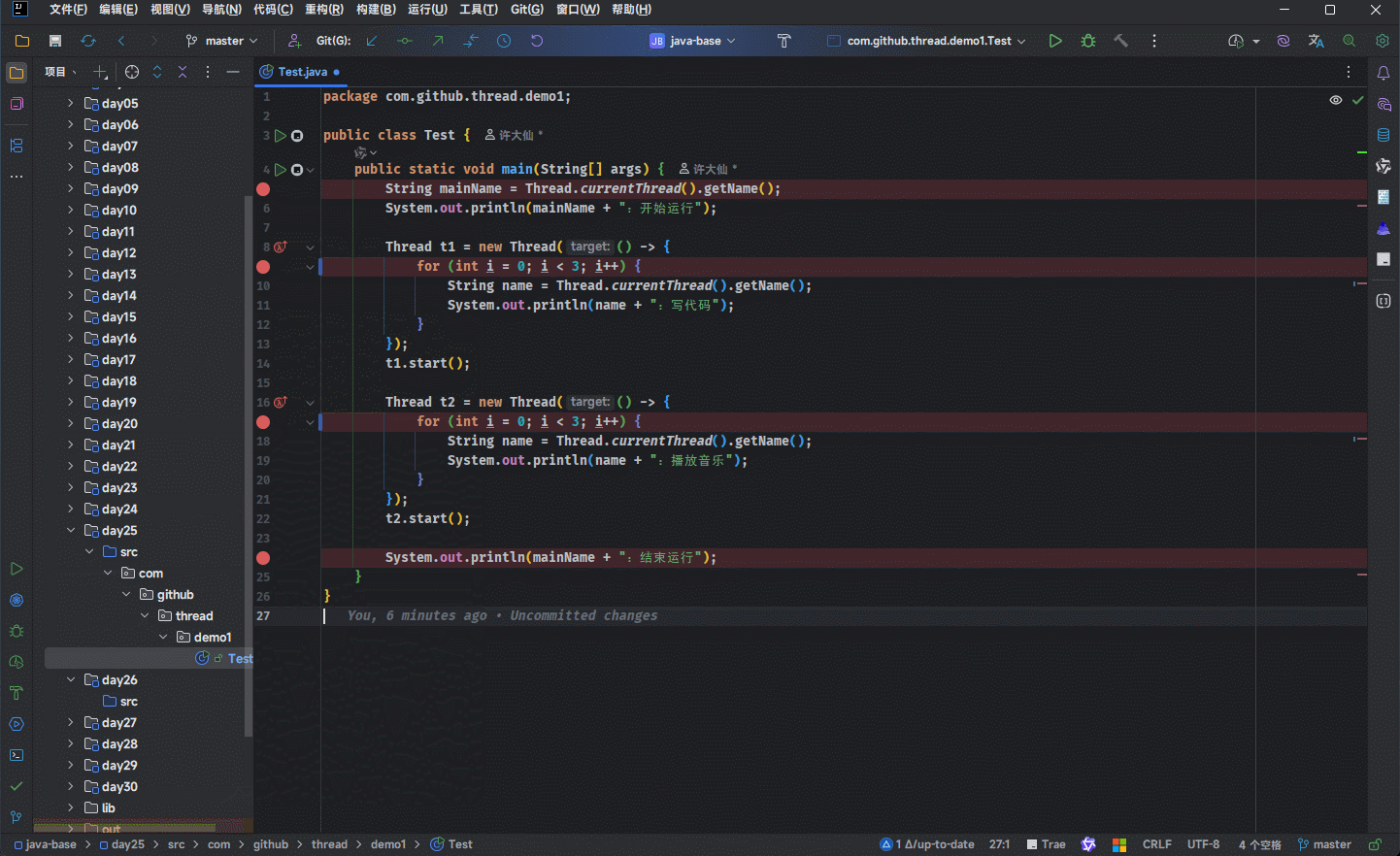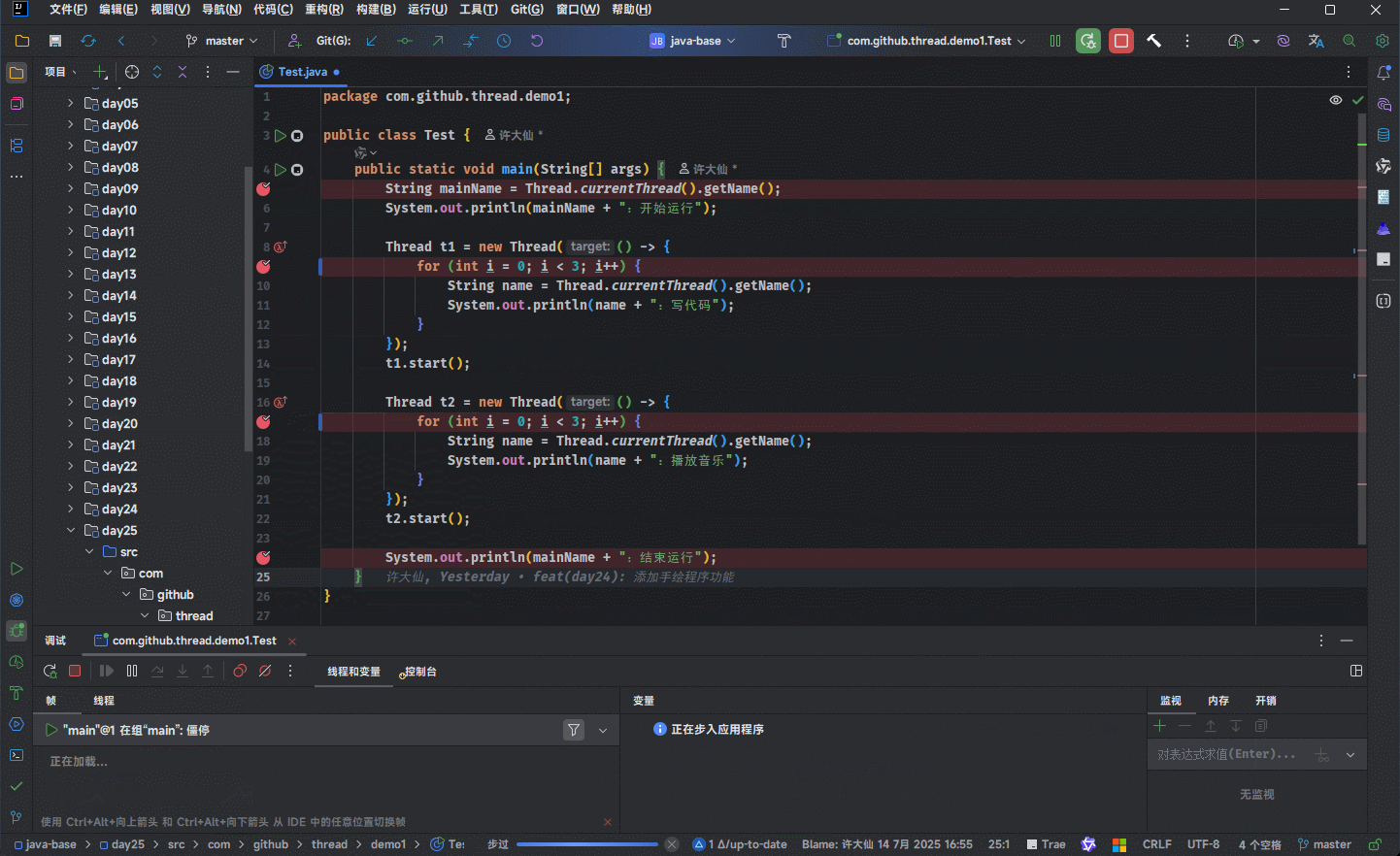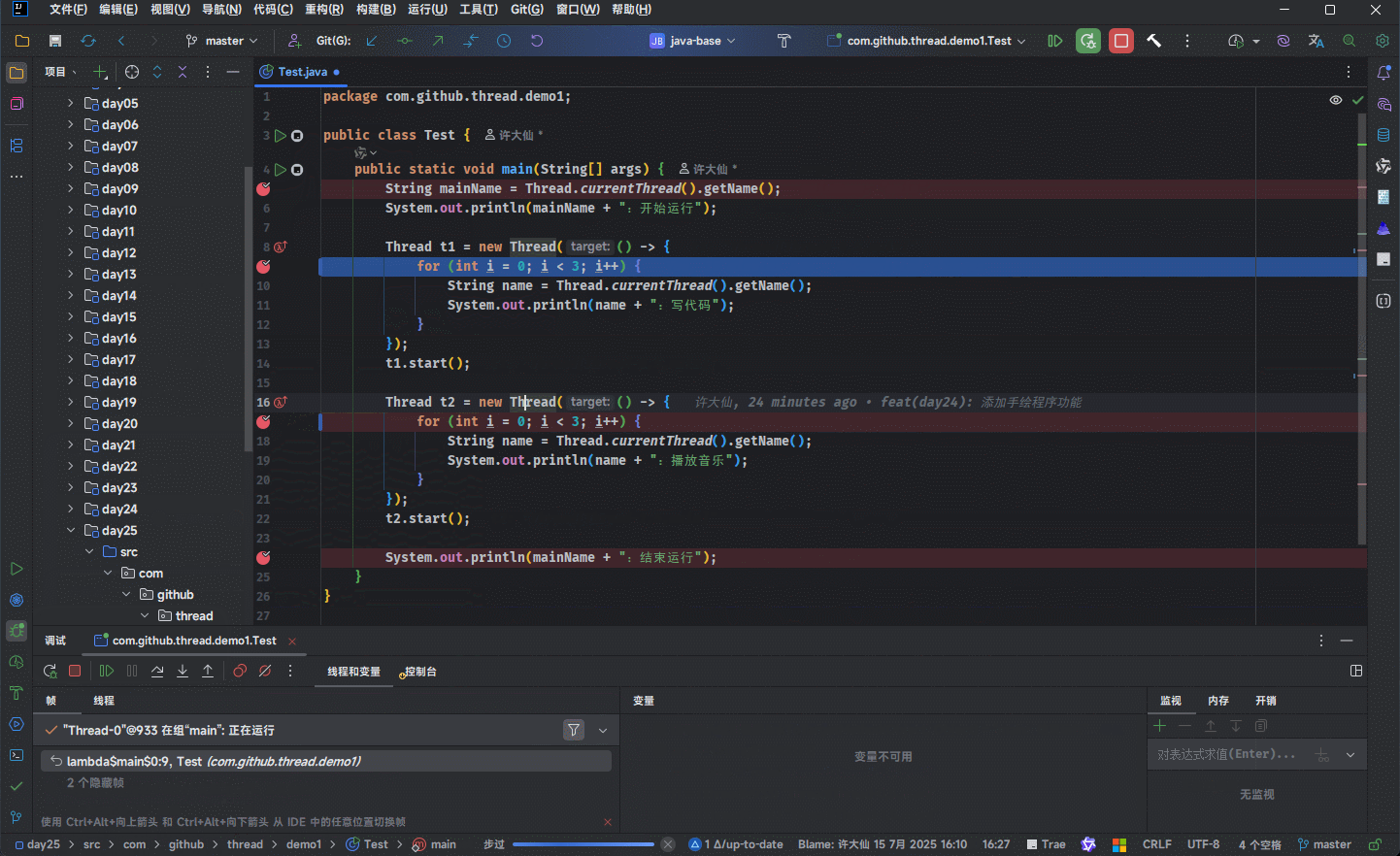
- 解决方案很简单,因为默认情况下,IDEA 的 debug 是 All(所有)级别,如下所示:
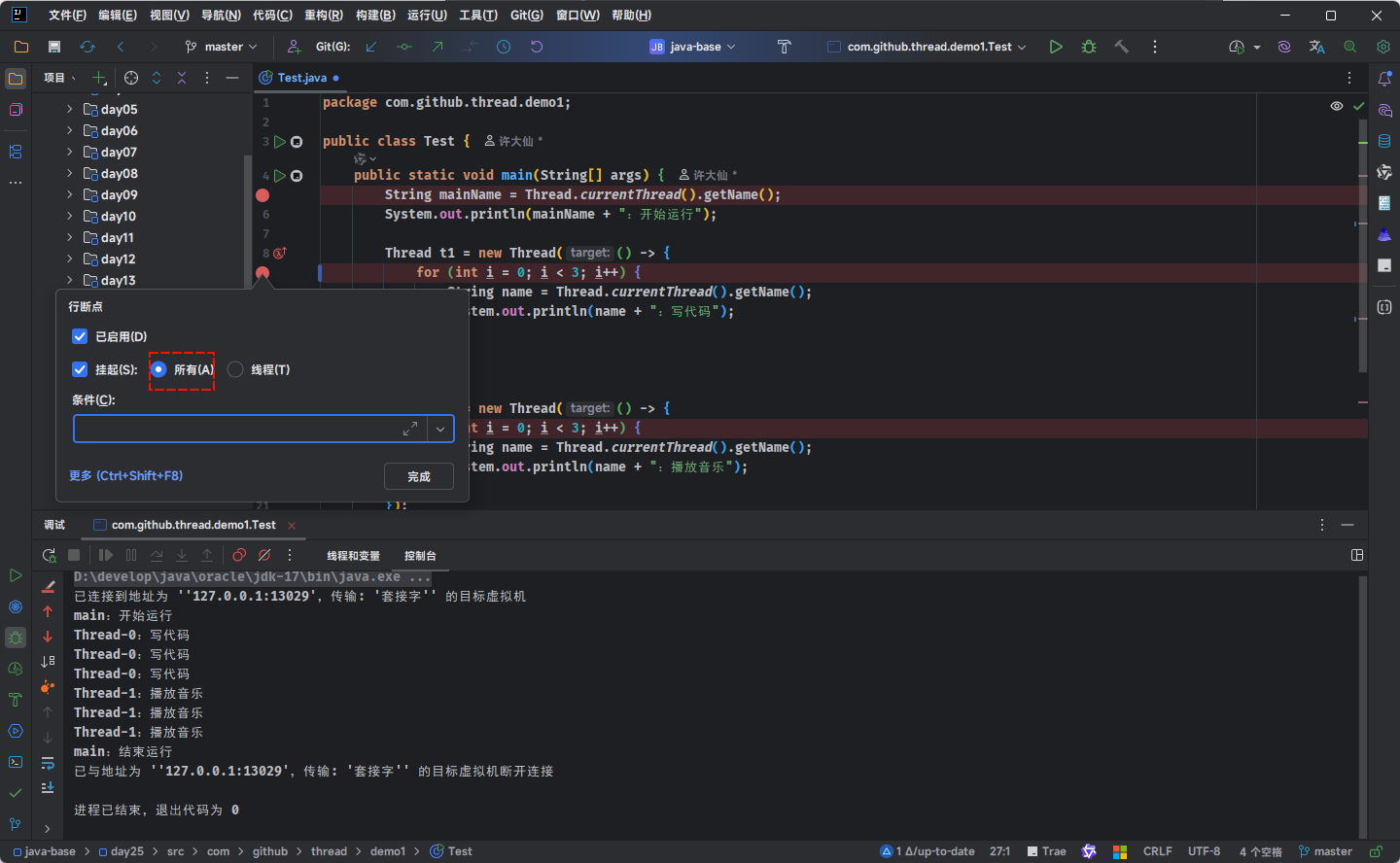
- 我们需要将 debug 级别改为 Thread(线程)级别;就可以进行多线程的 debug 调试: